Using features extracted from voice data of individuals to predict whether it is a man or a woman.

A voice recording is analyzed for many inferences like the content spoken, the emotion, gender, and identity of the speaker, and many more.
While recognizing the characteristics of the speaker from the recording, identity recognition requires a reference dataset and is limited to identifying the people in the dataset. In many cases, this level of specificity may not be needed.
Recognizing the speaker’s gender is one such use case. The model for the same can be trained to learn patterns and features specific to each gender and reproduce it for individuals who are not part of the training dataset too!
It finds applications in automatic salutations, tagging audio recording, and helping digital assistants reproduce male/female generic results.
In this article, we will be using acoustic features extracted from a voice recording to predict the speaker’s gender.
The implementation of the idea on cAInvas — here.
The dataset
(on Kaggle)
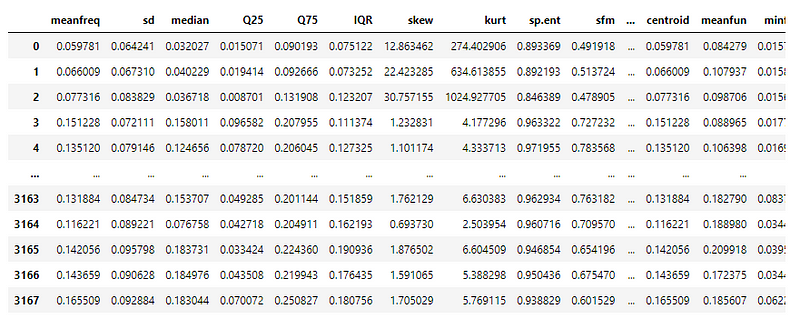
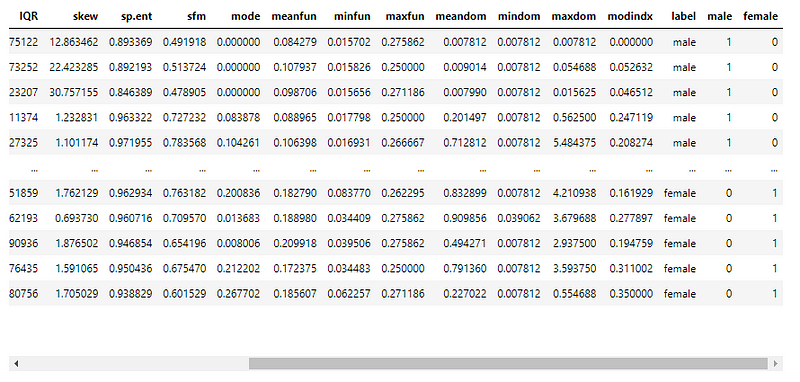
The dataset has 3168 voice samples recorded from both male and female speakers. These samples are then pre-processed using the acoustic analysis packages of R with an analyzed frequency range of 0hz-280hz (human vocal range) to extract around 20 features written to a CSV file.
A peek into the spread of samples across categories —

This is a perfectly balanced dataset.
Preprocessing
Correlation
A few pairs of columns have high correlation values. Thus we will be eliminating one of the two columns with a correlation value > 0.95.
The dataset has been edited to include only the final list of columns. The final dataset now has 18 columns — 17 attributes and 1 category column.
Defining the input features and output formats
The input and output columns are defined to separate the dataset into X and y later in the notebook.
The category column is one-hot encoded as the final layer of the model defined below has two nodes with the softmax activation function and uses the categorical cross-entropy loss.
We can alternatively use one node, sigmoid activation function, and binary cross-entropy loss.

These columns are inserted into the dataset making the total number of columns 20–17 attributes, 1 category column, and 2 one-hot encoded columns.
Splitting into train, validation, and test sets
We use 80–10–10 split to define training, validation, and test sets. The datasets are then split into their respective X and y arrays.
Scaling the attribute values
Since the individual features have values in different ranges, the min_max_scaler of the sklearn.preprocessing module is used to scale them in the range [0, 1].
The model
The model is a simple one with 3 dense layers, two of which have ReLU activation and one has Softmax activation.
The Adam optimizer with a 0.01 learning rate is used along with categorical cross-entropy loss. The accuracy metric is monitored.
Two callback functions of the keras.callbacks module is used — EarlyStopping tracks a value and stops the training if it doesn’t improve (increase/decrease according to the value tracked, like accuracy or loss). ModelCheckpoint saves the best model obtained yet, according to least val_loss (default). The saved model can be re-loaded later.
The number of epochs mentioned was 32 epochs but the model stopped training earlier.

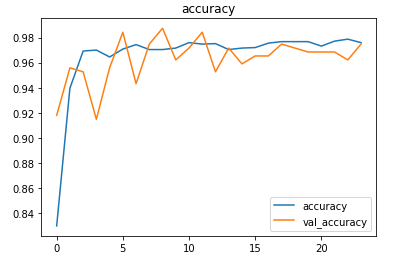
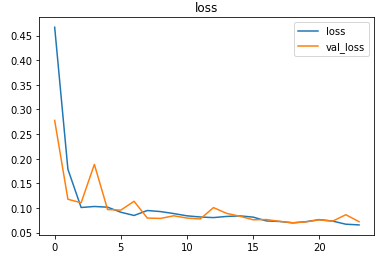
The metrics
Prediction
Let’s perform prediction on random test samples —

deepC
deepC library, compiler, and inference framework are designed to enable and perform deep learning neural networks by focussing on features of small form-factor devices like micro-controllers, eFPGAs, CPUs, and other embedded devices like raspberry-pi, odroid, Arduino, SparkFun Edge, RISC-V, mobile phones, x86 and arm laptops among others.
Compiling the model with deepC to get .exe file —

Head over to the cAInvas platform (link to notebook given earlier) and check out the predictions by the .exe file!
Credit: Ayisha D
Also Read: Age And Gender Prediction