Shape detection techniques are an important aspect of computer vision and are used to transform raw image data into the symbolic representations needed for object recognition and location.

In this article, a notebook is presented which contains the development of a system that detects four types of 3D shapes — Cube, Cylinder, Spheroid and Sphere.
The model used is built on top of mobilenet v1, leveraging the benefits of transfer learning inorder to build an a light weight but accurate CNN model.
Its implementation is done on the Cainvas Platform, which provides seamless execution of python notebooks to build AI systems which can eventually be deployed on the edge (i.e an embedded system such as compact MCUs).
The notebook can be found here.
Contents —
- Loading Mobilenet v1 as the Base Model
- Loading the Dataset
- Building a Model to be Fine-Tuned
- Training a Fine-Tuned Model using transfer learning.
- Testing the Final Model on Real-Life objects.
- Conclusion
Mobilenet v1 — Base Model
MobileNets are based on a streamlined architecture that uses depth-wise separable convolutions to build light weight deep neural networks.
The purpose behind using mobilenet for this use case is that, this project is intended to be deployed on mobile devices on the edge, hence making perfect sense to build a model based on a class of efficient models (MobileNets) that were pre-trained to suite deployment of Fine-Tuned DNN models for mobile and embedded vision applications.
Loading MobileNet:
Here the model parameters are set as follows
- IMAGE_SIZE = 224
- ALPHA = 0.75
- EPOCHS=20
3D Shapes Dataset
Dataset used here is a custom extracted dataset with images of the size (224,224). It consists of 4 directories which contain the images corresponding to the 4 classes of shapes.
All the images used for Training and Testing are pre-processed as follows:
Visualizing a sample of the Training Dataset:

Building the Model — Transfer Learning
The model to be fine-tune is built by adding a few extra layers to the base mobilenet model.
Here, we add 2 fully connected dense layers of 100 and 50 neurons respectively with a ‘relu’ activation function and a dropout of 0.5, to the last layer of mobilenet, and a final output layer for the predictions — which is another dense layer with 4 output neurons and ‘softmax’ activation function. (each neuron corresponding to an output class of shapes)
Training the Model — Fine-Tuning
Now that our transfer learning model is built, we can train (fine-tune) it on the dataset mentioned earlier using the keras ImageDataGenerator to preprocess the images even more to be suitable for our mobilenet model, thereby generating a training generator. (Code shown below)
The CNN model built earlier is now compiled with an adam optimizer, a categorical crossentropy loss and metric considered while training is the accuracy of the model.
The training generator defined is then fit into the model compiled as shown in the code below.
Summary of the model can viewed as the output before training is initiated within the notebook.
Finally the model is saved after training is completed as a keras model (.h5).
Testing the Model
The model achieves an accuracy of 99% and since its classification of just geometric shape of the object, it does not overfit even at such high levels of accuracy.
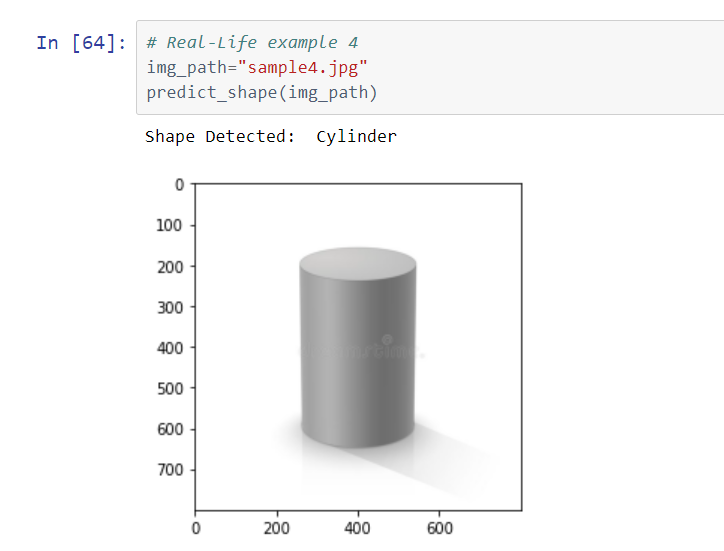
The model is tested on real-world objects as well as internet images to better understand its capabilities.
Following are the results:
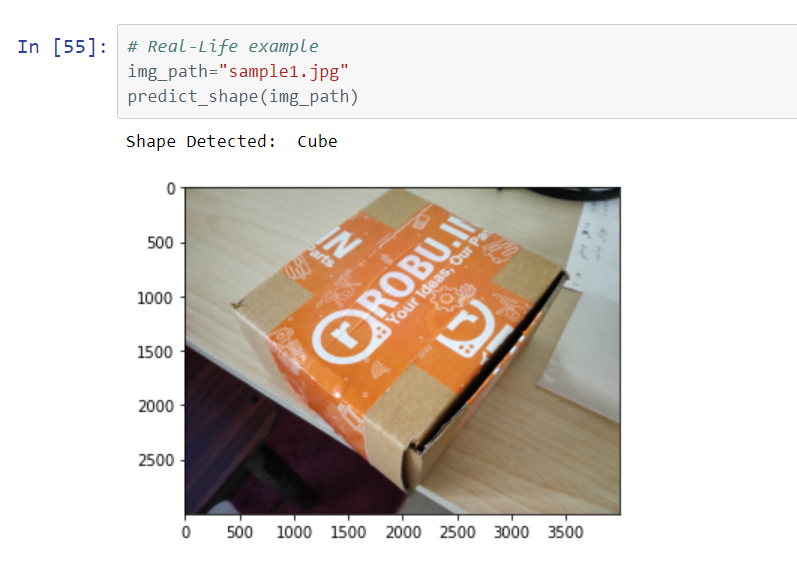
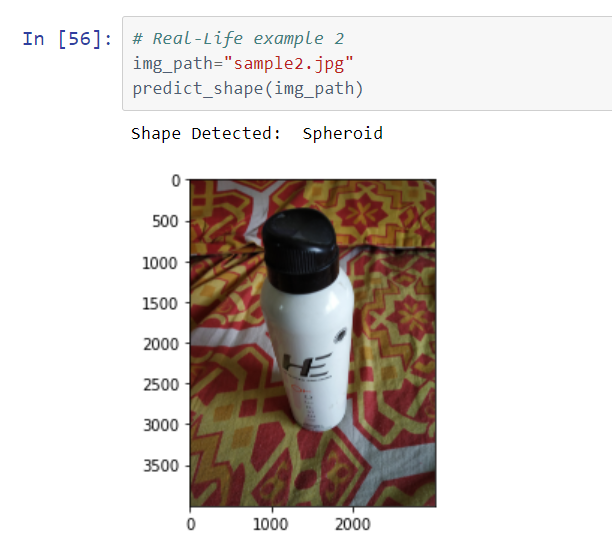
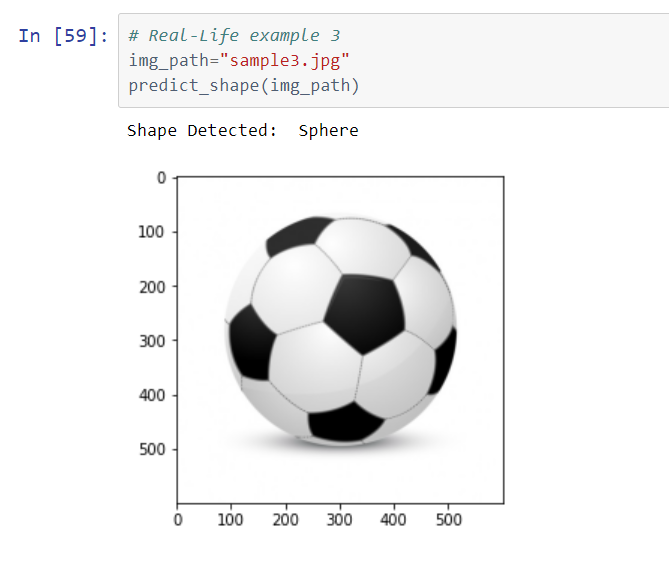
Conclusion
This 3D shape detection system can be used to classify objects even in real-time. Further advancements of this project would be to convert the keras CNN model to a minimal edge deployable model such as .tflite or .onnx inorder to deploy this onto an edge AIoT embedded module/MCU such as the OpenMV Cam or the Raspberry Pie.
This deployment is possible through the Cainvas Platform by making use of their compiler called deepC. Thus effectively bringing AI out on the edge — in actual and physical real world use cases.
Implementation of the idea on cAInvas is here!
Credit: Abdul Mannan Zafar