Using images of pomegranates and neural networks to assess their quality.

Fruits arrive in bulk at industries (like fruit juice or jam or any kind that uses fruit) and vary in quality from fresh to almost rotten.
It is important to categorize them based on their quality so as to not affect the taste and quality of the final manufactured product.
For example, a rotten orange can spoil the taste of the entire juice batch.
Here we use around 1080 images of pomegranates at different angles to determine their quality. Fruits of 3 grades (G1, G2, G3) are collected. Once the pomegranate fruits are collected they are then imaged for every alternate day up to a duration of eight days, leading into four qualities (Q1, Q2, Q3, Q4) for each grade.
Since the process is repeated for three grades, this resulted in a total of 12 classes of effective quality criteria, with four qualities within each grade.
Implementation of the idea on cAInvas here!
The dataset
Citation
[1] Kumar R, A., Rajpurohit, V. S., & Bidari, K. Y. (2019). Multi Class Grading and Quality Assessment of Pomegranate Fruits Based on Physical and Visual Parameters. International Journal of Fruit Science, 19(4), 372–396.
[2] Arun Kumar R, Vijay S. Rajpurohit, and Bhairu J. Jirage, “Pomegranate Fruit Quality Assessment Using Machine Intelligence and Wavelet Features,” Journal of Horticultural Research, vol. 26, no. 1, pp. 53–60, 2018. doi: 10.2478/johr-2018–0006
The dataset folder has 12 subfolders, each corresponding to one of the 12 classes. Each of these subfolders has 90 images.
Using the image_dataset_from_directory function of the keras.preprocessing module, we split the images into training and test set by specifying the dataset category and the split ratio.

A peek into the spread of values across the categories —
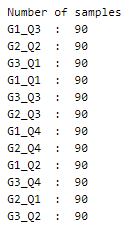
This is a perfectly balanced dataset!
Visualization
Let’s peek into the different categories of pomegranates in the dataset.



Preprocessing
The values of the image data array are integers in the range 0–255. Normalizing these values to the range [0, 1] using the rescaling function of the keras.layers.experimental.preprocessing. This helps in faster convergence of the model.
The model
Transfer learning is the concept of using a pre-trained model structure (and optionally the weight) to solve the problem at hand. The model may be trained on datasets different from the current problem but the knowledge gained has proven to be effective in solving problems in domains different from the ones used for training.
Here, we will be using the VGG16 model after removing its last layer (the classification layer) and attaching our own with 12 nodes in the last layer for the current problem.
The model uses Adam optimizer and the sparse categorical cross-entropy loss (as the category values are integers and not one-hot encoded). The accuracy of the predictions is tracked to evaluate the model’s performance.
The model is trained for 16 epochs with a learning rate of 0.1 and another 16 epochs with 0.01.
About 79% accuracy was obtained on the validation set.

A better result can be obtained with a larger training set or using augmentation techniques on the existing dataset.
The metrics
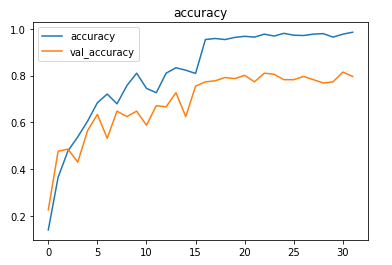
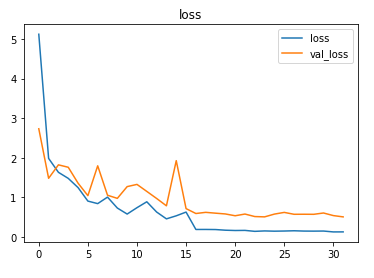
Prediction
Let us look at a random pomegranate image from the test dataset while the model predicts the quality/grade.

deepC
deepC library, compiler, and inference framework are designed to enable and perform deep learning neural networks by focussing on features of small form-factor devices like micro-controllers, eFPGAs, CPUs, and other embedded devices like raspberry-pi, odroid, Arduino, SparkFun Edge, RISC-V, mobile phones, x86 and arm laptops among others.
Compiling the model using deepC —

Head over to the cAInvas platform (link to notebook given earlier) to run and generate your own .exe file!
Credits: Ayisha D
Also Read: Signature Forgery Detection using Deep Learning