Detect the language of the given text data using deep neural networks.

Language detection refers to determining the language that the given text is written in. It is a text categorization problem at its core, with the languages being the classes.
This categorization becomes important when the language of the input data is not assumed. For example, the detect language feature of Google translate detects the language of the input text before translating it.
In this article, we classify text data into 22 languages — Arabic, Chinese, Dutch, English, Estonian, French, Hindi, Indonesian, Japanese, Korean, Latin, Persian, Portuguese, Pushto, Romanian, Russian, Spanish, Swedish, Tamil, Thai, Turkish, Urdu.
Implementation of the idea on cAInvas — here!
The dataset
WiLI-2018, the Wikipedia language identification benchmark dataset, contains 235000 paragraphs of 235 languages.
After data selection and preprocessing 22 languages from the original dataset were selected to create the current dataset.
Each language in this dataset contains 1000 rows/paragraphs. The dataset is a CSV file consisting of 1000 text samples from 22 languages each, making it a total of 22k samples in the dataset.

A peek into the spread of values across the classes —
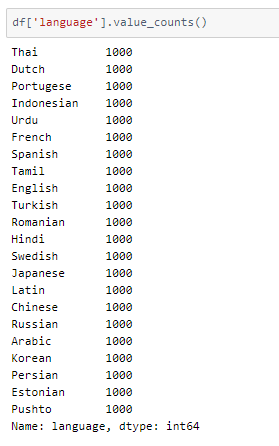
This is a perfectly balanced dataset.
Visualization
Here is one example text in each language from the dataset —


If we look closer into the samples, we can see that there are few English words in the Urdu sample and transliterated words in Thai too! This may lead to ambiguities during prediction.
Preprocessing
One hot encoding
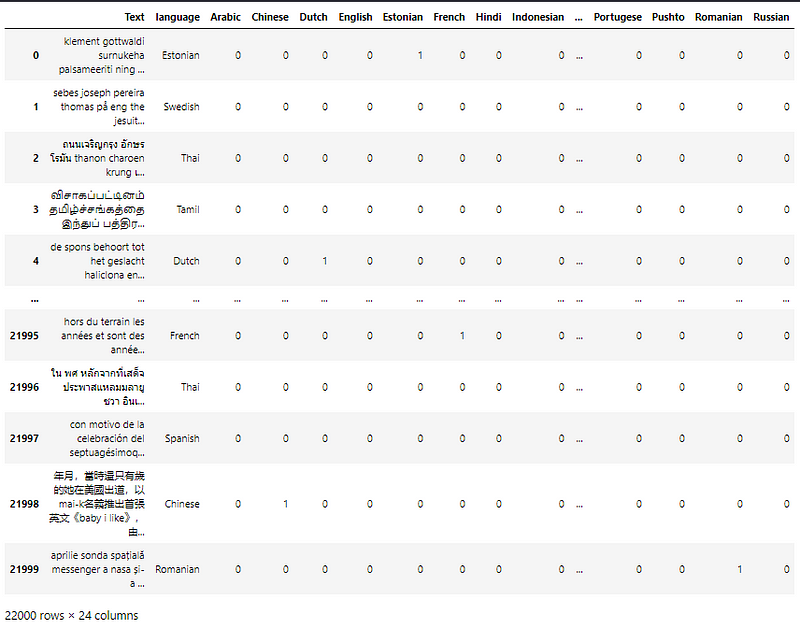
This is a multi-class classification problem where the classes do not have any range dependency. Thus the languages are one-hot encoded for classification purposes.
This is done using the get_dummies() function of the pandas module. The drop_first is kept False as this encoding is for the class labels.
The columns of the encoded column data frame are stored to help with decoding the output class values later on.
Bag of words encoding
The bag of words model represents the multiplicity of words in a sentence. The grammar or the order of words is not significant.
The CountVectorizer() function of the sklearn.feature_extraction.text module is used for its implementation. Only 1-gram (single word) tokens are used and the number of features extracted is limited to 20000.
Since logically, the training set is the only data we are allowed to see or work with while training the model while the other two are used to tweak/evaluate its performance, this model is fit on the training text data and used to transform all three text datasets — train, validation, and test.
Train-validation-test split
Using an 80–10–10 ratio to split the data frame into train-validation-test sets. These are then divided into X and y (input and output) for further processing.
Standardization
Standardization helps in centering and scaling the values to have a mean of 0 and a standard variance of 1. This ensures that no features get a higher weightage over another.
The StandardScaler function of the sklearn.preprocessing module is used to implement this concept. Similar to the bag of words encoding, the instance is fit on the training data and used to transform the train, validation, and test data.
The model
The model is a simple one with 4 Dense layers, 3 of which have ReLU activation functions and the last one has a Softmax activation function to convert the values of the final layer into a probability distribution.
The model is compiled using the categorical cross-entropy loss function because the final layer of the model has the softmax activation function and the labels are one-hot encoded. The Adam optimizer is used and the accuracy of the model is tracked over epochs.
The EarlyStopping callback function monitors the validation loss and stops the training if it doesn’t decrease for 5 epochs continuously. The restore_best_weights parameter ensures that the model with the least validation loss is restored to the model variable.
The model was trained first with a learning rate of 0.001 and then with a learning rate of 0.0001.
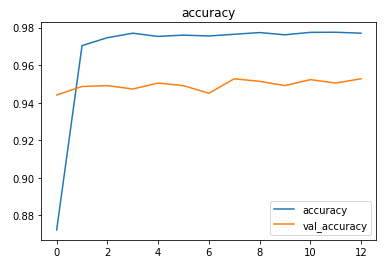
The model achieved an accuracy of ~94.7% on the test set.

A larger dataset would get us better results.
Plotting a confusion matrix to understand the results better —
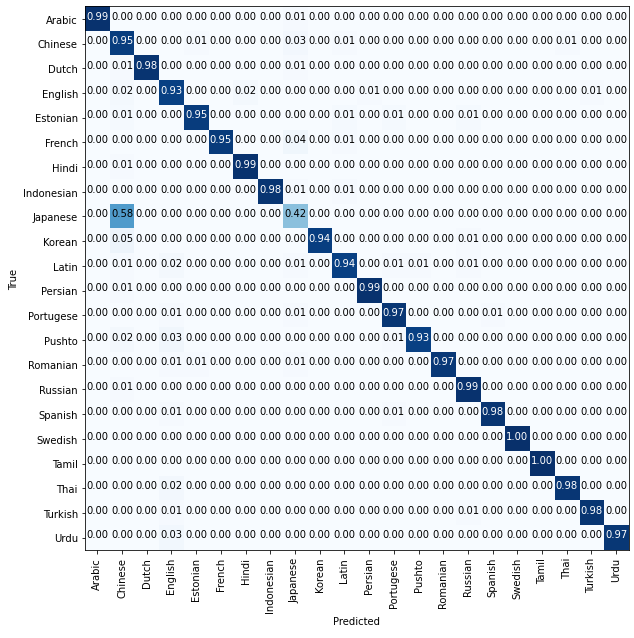
We can see that 3% of the Urdu texts were predicted to be English. This may be due to the discrepancies we saw in the dataset values earlier.
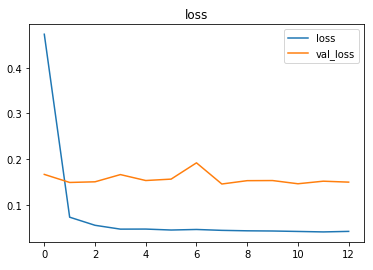
The metrics
Prediction
Let’s perform predictions on random test data samples —

deepC
deepC library, compiler, and inference framework are designed to enable and perform deep learning neural networks by focussing on features of small form-factor devices like micro-controllers, eFPGAs, CPUs, and other embedded devices like raspberry-pi, odroid, Arduino, SparkFun Edge, RISC-V, mobile phones, x86 and arm laptops among others.
Compiling the model using deepC —

Head over to the cAInvas platform (link to notebook given earlier) and check out the predictions by the .exe file!
Credits: Ayisha D