
This article presents a guide to Neural Style Transfer using Deep Learning. Neural Style Transfer is a technique of composing images in the style of another image. Neural Style Transfer takes three images as input, namely the image you want to stylise: the Content Image, a Style image, and a Combination Image, which is a copy of the Content Image initially.
The technique blends the Combination Image such that it resembles the Content Image painted in the style of Style Image. For example, let us take the following Content image: my image and the Udnie painting by Francis Picabia as the Style image.


The Combination Image will look something like the below image.

The flow of the article will be as follows: –
- Introduction to Neural Style Transfer — an Optimization Approach
- Various Loss Functions used
- Implementation
- Introduction to Fast Neural Style Transfer
- Model Architecture Used
- Using Pre-Trained models for styling images
- Results
- Conclusion
The complete code is present in this Cainvas notebook.
Introduction to Neural Style Transfer — an Optimization Approach
Leon Gatys et al. introduced the Neural Style Transfer technique in 2015 in “A Neural Algorithm of Artistic Style”. As stated earlier, Neural Style Transfer is a technique of composing images in the style of another image. A more formal definition as stated by Wikipedia is: –
Neural Style Transfer (NST) refers to a class of software algorithms that manipulate digital images or videos to adapt the appearance or visual style of another image. NST algorithms are characterized by their use of deep neural networks for the sake of image transformation.
If you want to go deep into the original technique, you can refer to the paper from this link.
As you might know, in a Convolutional Neural Network (CNN), Convolutional Layers followed by Activation, MaxPooling/AveragePooling layers perform the feature extraction task. Fully Connected layers follow these feature extraction layers for performing classification using the Softmax activation function.
So, as in Neural Style Transfer, we are more concerned with features of the images; intermediate convolutional layers of a pre-trained CNN model are used for feature extraction from the Content Image and the Style Image.
The original implementation of the technique used the VGG19 network as the pre-trained CNN model. In this article, I will be using the VGG16 network instead of VGG19.
The model architecture after removing the Fully Connected layers is presented below: –
Model: "model" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= input_1 (InputLayer) [(None, None, None, 3)] 0 _________________________________________________________________ block1_conv1 (Conv2D) (None, None, None, 64) 1792 _________________________________________________________________ block1_conv2 (Conv2D) (None, None, None, 64) 36928 _________________________________________________________________ block1_pool (MaxPooling2D) (None, None, None, 64) 0 _________________________________________________________________ block2_conv1 (Conv2D) (None, None, None, 128) 73856 _________________________________________________________________ block2_conv2 (Conv2D) (None, None, None, 128) 147584 _________________________________________________________________ block2_pool (MaxPooling2D) (None, None, None, 128) 0 _________________________________________________________________ block3_conv1 (Conv2D) (None, None, None, 256) 295168 _________________________________________________________________ block3_conv2 (Conv2D) (None, None, None, 256) 590080 _________________________________________________________________ block3_conv3 (Conv2D) (None, None, None, 256) 590080 _________________________________________________________________ block3_pool (MaxPooling2D) (None, None, None, 256) 0 _________________________________________________________________ block4_conv1 (Conv2D) (None, None, None, 512) 1180160 _________________________________________________________________ block4_conv2 (Conv2D) (None, None, None, 512) 2359808 _________________________________________________________________ block4_conv3 (Conv2D) (None, None, None, 512) 2359808 _________________________________________________________________ block4_pool (MaxPooling2D) (None, None, None, 512) 0 _________________________________________________________________ block5_conv1 (Conv2D) (None, None, None, 512) 2359808 _________________________________________________________________ block5_conv2 (Conv2D) (None, None, None, 512) 2359808 _________________________________________________________________ block5_conv3 (Conv2D) (None, None, None, 512) 2359808 _________________________________________________________________ block5_pool (MaxPooling2D) (None, None, None, 512) 0 ================================================================= Total params: 14,714,688 Trainable params: 14,714,688 Non-trainable params: 0 _________________________________________________________________
After extracting features from the Content Image, the Style Image, and the Combination Image, loss functions described in the following section are defined to minimise the losses.
Various Loss Functions Used
There are mainly two loss functions defined in the Neural Style Transfer technique —
- The Content Loss Function
- The Style Loss Function
The Content Loss Function
The content loss function defines the distance between the features extracted from the Content Image and Input Image. The content loss is simply the Euclidean distance between the characteristics of the Content Image and the Input Image.
We use the backpropagation technique for minimising this loss function so that the Input Image has almost the same content as the Content Image at the end of the algorithm.
The Style Loss Function
This function compares the Style Image features and the Input Image, as you might have guessed. The process of comparison is similar to the content loss function. However, this function uses the Gram Matrix for comparing features of both images.
We also use the backpropagation technique to ensure that the final image also has some Style Image features to minimise this loss function.
The total loss of the model is the summation of the content loss and the style loss.
Implementation
I have given a general introduction to the Optimization-based Neural Style Transfer technique in the previous sections. Now let us dive into the implementation part of the technique.
The first step is to import all the necessary libraries.
Loading the Input Image and the Style Image and displaying them using matplotlib
This will display the Style Image and the Input Image shown at the starting of this article.
The next step is to define functions for preprocessing the images to be fed to the model and deprocessing images to display the output image.
Then define the content loss function and the style loss function along with helper functions.
Loading the VGG16 model comes as the next step.
Specify the layers of the model for feature extraction and define the compute loss function.
Here, I have used ‘tf.GradientTape’ to provide automatic gradient generation of the loss function for the backpropagation technique.
Now the final step is to define the training loop.
As you can see in line 24, I have used the compute_loss_and_grads function to calculate the loss value and the gradients. And then, in line 27 applied these gradients for minimizing the loss value in further iterations.
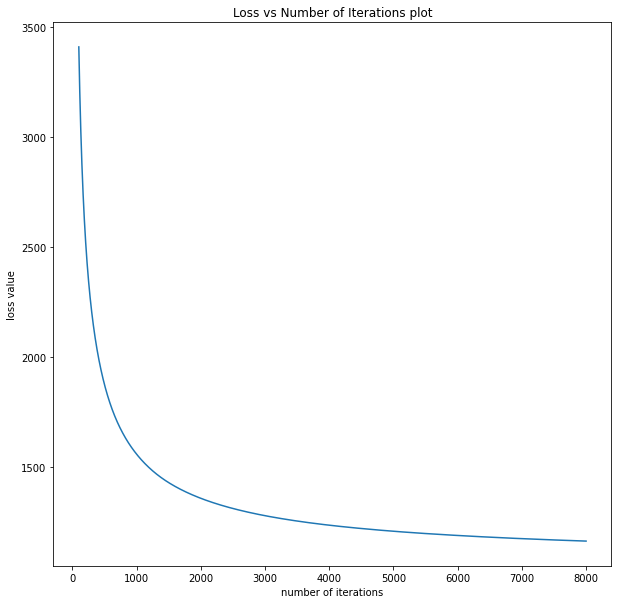
Additionally, the code prints the value of loss after every 100 iterations and at the 8000th iterations saves the final combination image in the directory. Stochastic Gradient Descent (SGD) with exponential decay works as the optimizer for the model, but you can also experiment with Adam or any other optimizer of your choice.
The loss value at the 100th iteration came out to be 3409.53, and at the 8000th iteration, it reduces to 1162.70.
The Loss value vs Number of Iterations plot is presented below: –
Now I show you the final combination image: –

Now you might be thinking that this output does not match the output image I showed in the starting. It is not even close! You may think at this point that you wasted your time reading this article and implementing a long method side by side and still not able to get good results.
However, I suggest that you keep reading, you have a long way in this article, and you are very close to the final result. I promise you will generate a similar image to the output image I presented earlier by the end of this article.
Introduction to Fast Neural Style Transfer
In the previous sections, I described the Optimization-based Neural Style Transfer technique. The technique has some drawbacks and limitations, which are described below: –
- Every time you change the Content Image you want to stylise, you have to rerun the whole process to generate the final combination image, which is a time-consuming approach and cannot be used for a deployable project.
- At the end of the previous section, I presented the result of the technique, which was not as good as you might expect. However, there is no doubt the method can also generate satisfying results, but you have to experiment with different style weight and content weight values. You have to use various image processing techniques to enhance the results.
Addressing these issues, Justin Johnson, Alexandre Alahi, Li Fei-Fei presented a paper at ECCV 2016 by the name ‘Perceptual Losses for Real-Time Style Transfer and Super-Resolution’.
Furthermore, Dmitry Ulyanov improved the method proposed in this paper in the paper ‘Instance Normalization: The Missing Ingredient for Fast Stylization’. I am not going into the details of these papers, but if you want to read these papers, you can click on the below links.
- Perceptual Losses for Real-Time Style Transfer and Super-Resolution
- Instance Normalization: The Missing Ingredient for Fast Stylization
The original implementation uses the VGG16 network with Microsoft COCO dataset having around 80k images and uses Adam optimiser with a learning rate of 0.001.
This GitHub repository provides the Fast Neural Style Transfer technique with Instance Normalization with various style images. I will be using the pre-trained models offered by this repository for stylising images instead of training the model again.
Model Architecture Used
Below is an overview of the network being used: –
Model: "vgg16"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_3 (InputLayer) [(None, 64, 64, 3)] 0
__________________________________________________________________________________________________
input_normalize_1 (InputNormali (None, 64, 64, 3) 0 input_3[0][0]
__________________________________________________________________________________________________
reflection_padding2d_4 (Reflect (None, 144, 144, 3) 0 input_normalize_1[0][0]
__________________________________________________________________________________________________
conv2d_16 (Conv2D) (None, 144, 144, 32) 7808 reflection_padding2d_4[0][0]
__________________________________________________________________________________________________
batch_normalization_16 (BatchNo (None, 144, 144, 32) 128 conv2d_16[0][0]
__________________________________________________________________________________________________
activation_11 (Activation) (None, 144, 144, 32) 0 batch_normalization_16[0][0]
__________________________________________________________________________________________________
conv2d_17 (Conv2D) (None, 72, 72, 64) 165952 activation_11[0][0]
__________________________________________________________________________________________________
batch_normalization_17 (BatchNo (None, 72, 72, 64) 256 conv2d_17[0][0]
__________________________________________________________________________________________________
activation_12 (Activation) (None, 72, 72, 64) 0 batch_normalization_17[0][0]
__________________________________________________________________________________________________
conv2d_18 (Conv2D) (None, 36, 36, 128) 73856 activation_12[0][0]
__________________________________________________________________________________________________
batch_normalization_18 (BatchNo (None, 36, 36, 128) 512 conv2d_18[0][0]
__________________________________________________________________________________________________
activation_13 (Activation) (None, 36, 36, 128) 0 batch_normalization_18[0][0]
__________________________________________________________________________________________________
conv2d_19 (Conv2D) (None, 34, 34, 128) 147584 activation_13[0][0]
__________________________________________________________________________________________________
batch_normalization_19 (BatchNo (None, 34, 34, 128) 512 conv2d_19[0][0]
__________________________________________________________________________________________________
activation_14 (Activation) (None, 34, 34, 128) 0 batch_normalization_19[0][0]
__________________________________________________________________________________________________
conv2d_20 (Conv2D) (None, 32, 32, 128) 147584 activation_14[0][0]
__________________________________________________________________________________________________
cropping2d_5 (Cropping2D) (None, 32, 32, 128) 0 activation_13[0][0]
__________________________________________________________________________________________________
batch_normalization_20 (BatchNo (None, 32, 32, 128) 512 conv2d_20[0][0]
__________________________________________________________________________________________________
add_5 (Add) (None, 32, 32, 128) 0 cropping2d_5[0][0]
batch_normalization_20[0][0]
__________________________________________________________________________________________________
conv2d_21 (Conv2D) (None, 30, 30, 128) 147584 add_5[0][0]
__________________________________________________________________________________________________
batch_normalization_21 (BatchNo (None, 30, 30, 128) 512 conv2d_21[0][0]
__________________________________________________________________________________________________
activation_15 (Activation) (None, 30, 30, 128) 0 batch_normalization_21[0][0]
__________________________________________________________________________________________________
conv2d_22 (Conv2D) (None, 28, 28, 128) 147584 activation_15[0][0]
__________________________________________________________________________________________________
cropping2d_6 (Cropping2D) (None, 28, 28, 128) 0 add_5[0][0]
__________________________________________________________________________________________________
batch_normalization_22 (BatchNo (None, 28, 28, 128) 512 conv2d_22[0][0]
__________________________________________________________________________________________________
add_6 (Add) (None, 28, 28, 128) 0 cropping2d_6[0][0]
batch_normalization_22[0][0]
__________________________________________________________________________________________________
conv2d_23 (Conv2D) (None, 26, 26, 128) 147584 add_6[0][0]
__________________________________________________________________________________________________
batch_normalization_23 (BatchNo (None, 26, 26, 128) 512 conv2d_23[0][0]
__________________________________________________________________________________________________
activation_16 (Activation) (None, 26, 26, 128) 0 batch_normalization_23[0][0]
__________________________________________________________________________________________________
conv2d_24 (Conv2D) (None, 24, 24, 128) 147584 activation_16[0][0]
__________________________________________________________________________________________________
cropping2d_7 (Cropping2D) (None, 24, 24, 128) 0 add_6[0][0]
__________________________________________________________________________________________________
batch_normalization_24 (BatchNo (None, 24, 24, 128) 512 conv2d_24[0][0]
__________________________________________________________________________________________________
add_7 (Add) (None, 24, 24, 128) 0 cropping2d_7[0][0]
batch_normalization_24[0][0]
__________________________________________________________________________________________________
conv2d_25 (Conv2D) (None, 22, 22, 128) 147584 add_7[0][0]
__________________________________________________________________________________________________
batch_normalization_25 (BatchNo (None, 22, 22, 128) 512 conv2d_25[0][0]
__________________________________________________________________________________________________
activation_17 (Activation) (None, 22, 22, 128) 0 batch_normalization_25[0][0]
__________________________________________________________________________________________________
conv2d_26 (Conv2D) (None, 20, 20, 128) 147584 activation_17[0][0]
__________________________________________________________________________________________________
cropping2d_8 (Cropping2D) (None, 20, 20, 128) 0 add_7[0][0]
__________________________________________________________________________________________________
batch_normalization_26 (BatchNo (None, 20, 20, 128) 512 conv2d_26[0][0]
__________________________________________________________________________________________________
add_8 (Add) (None, 20, 20, 128) 0 cropping2d_8[0][0]
batch_normalization_26[0][0]
__________________________________________________________________________________________________
conv2d_27 (Conv2D) (None, 18, 18, 128) 147584 add_8[0][0]
__________________________________________________________________________________________________
batch_normalization_27 (BatchNo (None, 18, 18, 128) 512 conv2d_27[0][0]
__________________________________________________________________________________________________
activation_18 (Activation) (None, 18, 18, 128) 0 batch_normalization_27[0][0]
__________________________________________________________________________________________________
conv2d_28 (Conv2D) (None, 16, 16, 128) 147584 activation_18[0][0]
__________________________________________________________________________________________________
cropping2d_9 (Cropping2D) (None, 16, 16, 128) 0 add_8[0][0]
__________________________________________________________________________________________________
batch_normalization_28 (BatchNo (None, 16, 16, 128) 512 conv2d_28[0][0]
__________________________________________________________________________________________________
add_9 (Add) (None, 16, 16, 128) 0 cropping2d_9[0][0]
batch_normalization_28[0][0]
__________________________________________________________________________________________________
un_pooling2d_3 (UnPooling2D) (None, 32, 32, 128) 0 add_9[0][0]
__________________________________________________________________________________________________
reflection_padding2d_5 (Reflect (None, 36, 36, 128) 0 un_pooling2d_3[0][0]
__________________________________________________________________________________________________
conv2d_29 (Conv2D) (None, 34, 34, 64) 73792 reflection_padding2d_5[0][0]
__________________________________________________________________________________________________
batch_normalization_29 (BatchNo (None, 34, 34, 64) 256 conv2d_29[0][0]
__________________________________________________________________________________________________
activation_19 (Activation) (None, 34, 34, 64) 0 batch_normalization_29[0][0]
__________________________________________________________________________________________________
un_pooling2d_4 (UnPooling2D) (None, 68, 68, 64) 0 activation_19[0][0]
__________________________________________________________________________________________________
reflection_padding2d_6 (Reflect (None, 72, 72, 64) 0 un_pooling2d_4[0][0]
__________________________________________________________________________________________________
conv2d_30 (Conv2D) (None, 70, 70, 32) 18464 reflection_padding2d_6[0][0]
__________________________________________________________________________________________________
batch_normalization_30 (BatchNo (None, 70, 70, 32) 128 conv2d_30[0][0]
__________________________________________________________________________________________________
activation_20 (Activation) (None, 70, 70, 32) 0 batch_normalization_30[0][0]
__________________________________________________________________________________________________
un_pooling2d_5 (UnPooling2D) (None, 70, 70, 32) 0 activation_20[0][0]
__________________________________________________________________________________________________
reflection_padding2d_7 (Reflect (None, 72, 72, 32) 0 un_pooling2d_5[0][0]
__________________________________________________________________________________________________
conv2d_31 (Conv2D) (None, 64, 64, 3) 7779 reflection_padding2d_7[0][0]
__________________________________________________________________________________________________
batch_normalization_31 (BatchNo (None, 64, 64, 3) 12 conv2d_31[0][0]
__________________________________________________________________________________________________
activation_21 (Activation) (None, 64, 64, 3) 0 batch_normalization_31[0][0]
__________________________________________________________________________________________________
transform_output (Denormalize) (None, 64, 64, 3) 0 activation_21[0][0]
__________________________________________________________________________________________________
concatenate (Concatenate) (None, 64, 64, 3) 0 transform_output[0][0]
input_3[0][0]
__________________________________________________________________________________________________
vgg_normalize (VGGNormalize) (None, 64, 64, 3) 0 concatenate[0][0]
__________________________________________________________________________________________________
block1_conv1 (Conv2D) (None, 64, 64, 64) 1792 vgg_normalize[0][0]
__________________________________________________________________________________________________
block1_conv2 (Conv2D) (None, 64, 64, 64) 36928 block1_conv1[0][0]
__________________________________________________________________________________________________
block1_pool (MaxPooling2D) (None, 32, 32, 64) 0 block1_conv2[0][0]
__________________________________________________________________________________________________
block2_conv1 (Conv2D) (None, 32, 32, 128) 73856 block1_pool[0][0]
__________________________________________________________________________________________________
block2_conv2 (Conv2D) (None, 32, 32, 128) 147584 block2_conv1[0][0]
__________________________________________________________________________________________________
block2_pool (MaxPooling2D) (None, 16, 16, 128) 0 block2_conv2[0][0]
__________________________________________________________________________________________________
block3_conv1 (Conv2D) (None, 16, 16, 256) 295168 block2_pool[0][0]
__________________________________________________________________________________________________
block3_conv2 (Conv2D) (None, 16, 16, 256) 590080 block3_conv1[0][0]
__________________________________________________________________________________________________
block3_conv3 (Conv2D) (None, 16, 16, 256) 590080 block3_conv2[0][0]
__________________________________________________________________________________________________
block3_pool (MaxPooling2D) (None, 8, 8, 256) 0 block3_conv3[0][0]
__________________________________________________________________________________________________
block4_conv1 (Conv2D) (None, 8, 8, 512) 1180160 block3_pool[0][0]
__________________________________________________________________________________________________
block4_conv2 (Conv2D) (None, 8, 8, 512) 2359808 block4_conv1[0][0]
__________________________________________________________________________________________________
block4_conv3 (Conv2D) (None, 8, 8, 512) 2359808 block4_conv2[0][0]
__________________________________________________________________________________________________
block4_pool (MaxPooling2D) (None, 4, 4, 512) 0 block4_conv3[0][0]
__________________________________________________________________________________________________
block5_conv1 (Conv2D) (None, 4, 4, 512) 2359808 block4_pool[0][0]
__________________________________________________________________________________________________
block5_conv2 (Conv2D) (None, 4, 4, 512) 2359808 block5_conv1[0][0]
__________________________________________________________________________________________________
block5_conv3 (Conv2D) (None, 4, 4, 512) 2359808 block5_conv2[0][0]
__________________________________________________________________________________________________
block5_pool (MaxPooling2D) (None, 2, 2, 512) 0 block5_conv3[0][0]
==================================================================================================
Total params: 16,544,591
Trainable params: 16,541,385
Non-trainable params: 3,206
__________________________________________________________________________________________________
Using Pre-Trained Model for Styling Image
I will be using the pre-trained PyTorch model for the Udnie Style Image from the GitHub repository mentioned above. Following is the implementation of the same.
Firstly load the trained model and the input image using OpenCV. Then feed-forward the image to the model by creating a blob using cv2.dnn.blobFromImage() function.
Finally, process the output image and display the input image along with the final combination image.
Results
The output image generated by the model and displayed by the last few lines of code: –
This image is the same image I showed in the starting. As I promised earlier, you will generate good results towards the end of the article. Here it is! Now you can generate some excellent stylised images.
The GitHub repository for the Fast Neural Style Transfer provides around ten pre-trained models for various style images. You can try them also and compare the results. Alternatively, you can train the model for a different style image for which a pre-trained model does not exist by using the repository’s training code.
Conclusion
This article presented two different methods for Neural Style Transfer, namely Optimization-based approach and Fast Neural Style Transfer. The optimization-based process is slow as the model needs to be trained every time the input image changes.
On the other hand, the Fast Neural Style transfer model is already trained for a particular style image with several input images. So it can be used to generalize results without retraining the model. However, you need to retrain the model if you change the style image and a pre-trained model is unavailable.
Thank you very much for reading this article. If you liked the article, please share it with friends who may be interested in this topic. And do let us know if you have any suggestions.
Notebook Link: Here
Credit: YUVNISH MALHOTRA
Also Read: Traffic Sign Classifier