
An oil spill is the release of a liquid petroleum hydrocarbon into the environment, especially the marine ecosystem, due to human activity, and is a form of pollution. The term is usually given to marine oil spills, where oil is released into the ocean or coastal waters, but spills may also occur on land.
Oil spills may be due to releases of crude oil from tankers, offshore platforms, drilling rigs and wells, as well as spills of refined petroleum products (such as gasoline, diesel) and their by-products, heavier fuels used by large ships such as bunker fuel, or the spill of any oily refuse or waste oil.
Oil spills penetrate into the structure of the plumage of birds and the fur of mammals, reducing its insulating ability, and making them more vulnerable to temperature fluctuations and much less buoyant in the water.
Cleanup and recovery from an oil spill is difficult and depends upon many factors, including the type of oil spilled, the temperature of the water (affecting evaporation and bio-degradation), and the types of shorelines and beaches involved. Spills may take weeks, months or even years to clean up.
By using ML and Deep Learning we can overcome these problem
Lets have a look at the dataset
The training set consists of 60000 observations and 170 sensor values. These sensors are classified into 2 types:
measure:single measurement for the sensor.histogram bin:A set of 10 columns that are different bins of a sensor that show their distribution over time.
The job is to classify whether the observation is a failure or not failure. The histogram below shows the train set distribution:

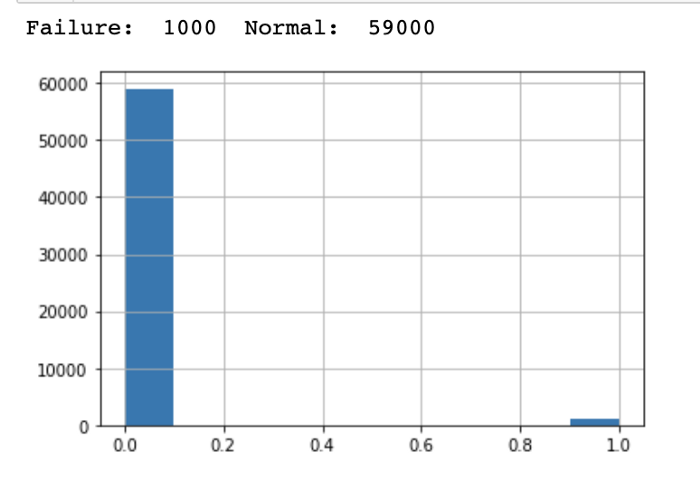
The data contains many null values. I have to create a function that takes in the different thresholds, treats missing values case-by-case, and hyper-tuning this function for the optimal result. I used xgboost to make the prediction withf1-score as the metric.
Preprocessing and baseline
Using vtreat for preprocessing an then creating baseline random forest, XGB-Classifier and Logistic Regression.
Model
Now let’s use cross-validation to choose the best model
Then Hyper-tuning the na function
Prediction
Since the best model is XGB Classifier, lets move on with the same model.
XGBClassifier(base_score=0.5, booster=\'gbtree\', colsample_bylevel=1,
colsample_bynode=1, colsample_bytree=1, gamma=0,
learning_rate=0.1, max_delta_step=0, max_depth=4,
min_child_weight=1, missing=None, n_estimators=200, n_jobs=1,
nthread=None, objective=\'binary:logistic\', random_state=0,
reg_alpha=0, reg_lambda=1, scale_pos_weight=1, seed=None,
silent=None, subsample=1, verbosity=1)
Notebook: Here
Credit: vishal yadav
Also Read: Sheep Detection