
Pedestrian detection is a subfield of object detection and plays an important role in various applications such as intelligent surveillance systems, person tracking, abnormal-scene detection, and intelligent cars.
The objective of this study is to design a convolutional neural network model which can classify images as persons or person-like from various other figures with human-like appearances.
Here, the CNN model was trained with a dataset containing images of persons and person-like objects and performed very well in both the train and validation datasets.
About the dataset
This dataset was prepared by N. J. Karthika and Saravanan Chandran. The reason for being prepared for this dataset was to address false positives that occur during the person detection process.
Generally, some objects have very similar features to that of a person or we can say these objects have almost the same appearances as that of a human being. Since, if a model is trained using a dataset containing only a person’s images, it can lead to several false positives predictions as it cannot differentiate other objects with a person-like appearance from that of a real person’s images.
This dataset includes both person and person-like objects. The person-like objects that were introduced in this dataset include statues, mannequins, robots, and scarecrows.
As per parameters, this dataset consists of 944 images in the training set, 160 images in the validation set, and 235 images in the test set, with a total of 1626 person and 1368 person-like labeling.

Dataset size is 190 MB.
Data Preprocessing
In this dataset, we were provided three directories, namely “Train”, “Test” and “Val” i.e Validation. Here, each directory consists of three entities that store some information about that image. The three entities are described below:
- Annotations, this is a directory that contains a separate XML file for every image. This file contains all the information about the image.
- JPEGImages, this directory contains the images.
- .txt file, this is a text file, it stores a unique serial number for every single image.
Hence, as we are already provided with the separate training, validation, and test data, there is no need to split this dataset anymore. So, we can directly load all the data by defining a simple loading function as described below.
Defining the CNN Model
For this classification model, we defined a convolutional neural network model with “ReLU” as an activation function.
Here, we used “sparse categorical cross-entropy” instead of “categorical cross-entropy” for the compilation of our model, and “Adam” is used as an optimizer.
Generally, the use entirely depends on how the dataset is loaded. One advantage of using sparse categorical cross-entropy is that it saves time in memory as well as computation because it simply uses a single integer for a class, instead of using a whole vector.
Callbacks
Here we used multiple callbacks, as per the technical definition, a callback is simply an object that can perform actions at various stages of training(e.g. at the start or end of an epoch, before or after a single batch, etc).
- Early Stopping: Used to stop training when a monitored metric has stopped improving.
- Reduce LR On Plateau: Used to reduce learning rate when a metric has stopped improving.
- Model Checkpoint: Used to save the Keras model or model weights at some frequency.
Model Summary
Below, is the summary of our convolutional neural network model.
Inference
The model achieved an exceptional accuracy of 99% on the test set and 70% of accuracy on the validation set.
Plotting Graphs
The graph between loss, accuracy, validation loss, and validation accuracy.
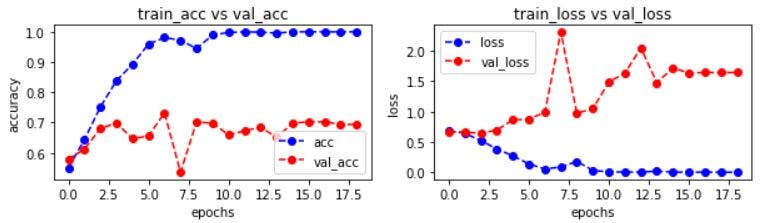
- “loss” represented training loss
- “acc” represented training accuracy
- “val_loss” represented validation accuracy
- “val_acc” represented validation accuracy
Model Predictions
Below I defined a function to validate our convolutional neural network model on the validation set. Here, we can see that most of the images classified by our model are correct. Also, as there is always room for improvement, this model can perform better with a larger dataset.

Notebook Link: Here
Credit: Akash Rawat
Also Read: Fall Detection using CNN architecture