Are they being sarcastic?

Sarcasm is the use of words that convey a meaning opposite to the one you actually intend to pass on. It has the ability to flip the sentiment of the sentence. This makes sarcasm detection an important part of sentiment analysis.
Most of the datasets available for this purpose rely on tweets written by the public. This can result in noisy data with improper labeling. The context of tweets is dependent on the thread (in case of replies) and thus, understanding the context of the conversation becomes crucial to labeling the text.
To overcome this, here we use a dataset consisting of news headlines. This is a comparatively reliable dataset as the headlines are written by professionals and the source can be used in labeling the dataset samples.
Implementation of the idea on cAInvas — here!
The dataset
This dataset is collected from two news websites. The Onion aims at producing sarcastic versions of current events and the headlines from the News in Brief and News in Photos categories (which are sarcastic) were collected. Also, real (and non-sarcastic) news headlines were collected from HuffPost.
Looking into the distribution of class values —
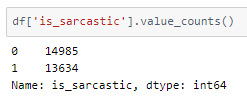
It is an almost balanced dataset. Good to go!
Data preprocessing
The headline text has to be cleaned, i.e., URLs and HTML elements removed (if any). Next, the text is stripped of any character that is not an alphabet. The functions for the same are defined as follows —
Once the above preprocessing is done, the sentence is converted to lowercase before stemming it into the root word. This helps in identifying words that are different forms of the same word (for example, eat, eating, ate, etc.). Snowball stemmer of the nltk.stem module is used for stemming.
Stopwords are not removed as they can help in delivering the context of the sentence as a whole.
The words belonging to each of the classes are stored separately for visualization using WordCloud
The size of the word is proportional to its frequency in the dataset. It is not possible to derive any inference based on these images.
Train-validation split
Splitting the dataset into train and validation sets using 80–20 ratio.
The train set has 22895 samples and the validation set has 5724 samples.
Tokenization
The Tokenizer function of the keras.preprocessing.text module is used to convert the text into a sequence of integers to give as input to the model. They are then padded with zeros to achieve a maximum length of 200.
The model
The model to be trained consists of an embedding layer that converts the input samples (sparse) into dense arrays of fixed size. This is followed by an LSTM and three Dense layers, the first two having ReLU activation and the last one having Sigmoid activation functions.
The model is compiled using the BinaryCrossentropy loss as there are only two classes — 0 and 1. Adam optimizer is used and the model’s accuracy is tracked.
The EarlyStopping callback function of the keras.callbacks module tracks a metric (here, val_loss by default) for the given number of epochs and stops training if the metric doesn’t improve (decrease if loss, increase if accuracy). The restore_best_weights parameter ensures that the model with the least validation loss (or best value of metric) yet is restored to the model variable.
The model achieved ~83.5% accuracy on the test set after training with a learning rate of 0.01.

Peeking into the confusion matrix to understand the results better —
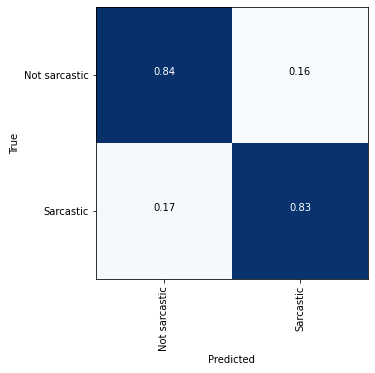
The metrics
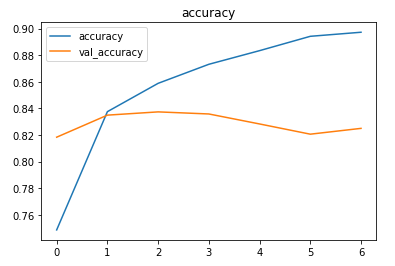
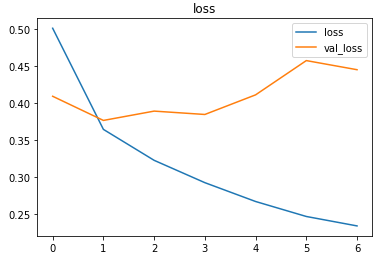
Prediction
Performing predictions on random test samples —

deepC
deepC library, compiler, and inference framework are designed to enable and perform deep learning neural networks by focussing on features of small form-factor devices like micro-controllers, eFPGAs, CPUs, and other embedded devices like raspberry-pi, odroid, Arduino, SparkFun Edge, RISC-V, mobile phones, x86 and arm laptops among others.
Compiling the model using deepC —
Head over to the cAInvas platform (link to notebook given earlier) to run and generate your own .exe file!
Credits: Ayisha D