Classifying recyclable waste materials based on images.

Garbage disposal is a huge problem in today’s world. As the population grows, the waste generated increases and proper treatment and disposal of the generated waste is important to ensure negligible, if not no harm to the environment.
The three Rs is a well-known concept when it comes to monitoring the amount of waste. Reduce the waste generated by avoiding disposables or over-packaged goods, buy recycled products, and contribute towards collection centers that work towards recycling products, and reuse materials whenever possible.
In this article, we will be classifying the recyclable products into categories based on their materials. This sorting is necessary because each material has its own recycling treatments and procedures.
The materials mentioned in this notebook are glass, cardboard, paper, plastic, and metal.
Here is a link to the implementation on cAInvas — here.
The dataset
(Dataset on Kaggle)
The dataset link in the notebook points to a zip file that contains two folders, train and test, each with five subfolders, one for each material, glass, cardboard, paper, plastic, and metal.
The training folder has a total of 1910 images and the test folder has 480 images.
The image_dataset_from_directory function of the keras.preprocessing module provides an easy way to load images separated into well-defined folders like the ones in our dataset.
The distribution of images among the labels are as follows —

The dataset is a little unbalanced.
The images are of the size 256×256. Some sample images from the dataset for a visual idea —

Preprocessing
The image data array has values in the range of 0–255. Normalizing these values to the range [0, 1] can help the model to converge faster.
The model
Transfer learning is the concept of using a pre-trained model structure (and weight, optional) to solve the problem at hand. The model may be trained on datasets different from the current problem but the knowledge gained has proven to be effective in solving problems in domains different from the ones used for training.
Here, we will be using the Xception model after removing its last layer (the classification layer) and attaching our own as necessary for the current problem.
The Xception model’s weights will be kept intact while the layers we appended at the end will be trained.
The model uses sparse categorical cross-entropy loss as the labels are not one hot encoded to represent classes. Adam optimizer was used and the model’s accuracy metric was tracked to review performance.
The model was trained for 8 epochs with a 0.001 learning rate. Around 87% accuracy was achieved on the test set.

Higher accuracy can be achieved with more training data or by applying data augmentation techniques (discussed in the rice leaf disease detection app) in the existing one.
The metrics
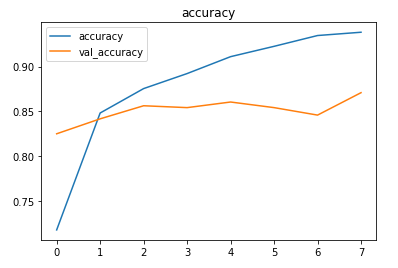
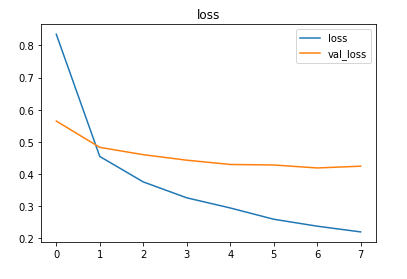
Prediction
Let us look at the test image along with the model’s predictions —

Looks like the prediction was a close call!
deepC
deepC library, compiler, and inference framework are designed to enable and perform deep learning neural networks by focussing on features of small form-factor devices like micro-controllers, eFPGAs, CPUs, and other embedded devices like raspberry-pi, odroid, Arduino, SparkFun Edge, RISC-V, mobile phones, x86 and arm laptops among others.
Compiling the model using deepC —

Head over to the cAInvas platform (link to notebook given earlier) to run and generate your own .exe file!
Credits: Ayisha D
Also Read: Parkinson’s disease detection — on cAInvas