Handwritten Character Recognition is often considered as the “Hello World” of Modern Day Deep Learning. Handwritten Optical Character Recognition has been studied by researchers and Deep Learning practitioners for decades now.
It is by far the most understood area in Deep Learning and pattern recognition. Anyone starting with Deep Learning encounters the MNIST dataset that contains highly processed images of handwritten digits.
The MNIST dataset was created in 1998. Some Deep Learning methods have achieved a near-human level performance on this dataset. Researchers now use this dataset as a benchmark and baseline dataset for testing new Deep Learning and Machine Learning models.
According to Wikipedia —
Optical character recognition or optical character reader (OCR) is the electronic or mechanical conversion of images of typed, handwritten or printed text into machine-encoded text, whether from a scanned document, a photo of a document, a scene-photo (for example the text on signs and billboards in a landscape photo) or from subtitle text superimposed on an image (for example: from a television broadcast)
Most Handwritten Optical Character Recognition methods aim to effectively segment and recognize the handwritten characters in an image or document. This article takes one step forward by segmenting and recognizing handwritten digits and some mathematical operators and calculating the value of the mathematical expression written.
The project aims at building a CNN model architecture and a pipeline for expression value calculation. Optimizing the model to reduce the number of trainable parameters of the CNN model to below 250k is one of the project’s primary goals for easy deployment to edge or less computation efficient devices.
The Cainvas Platform is used for implementation, which provides seamless execution of python notebooks for building AI systems that can eventually be deployed on edge (i.e. an embedded system such as compact MCUs).
The notebook can be found here.
The flow of the article will be as follows —
- Description of the Project
- The Dataset
- Preprocessing Step
- Building the CNN model
- Training the Model
- Model Performance
- Testing on Images
- Building Pipeline for Segmentation and Expression Calculation
- Conclusion
Description of the Project
The project aims at segmenting and recognizing handwritten digits and mathematical operators in an image. Finally, creating a pipeline for calculating the value of the expression written.
The current implementation recognizes only four basic mathematical operators namely Add(+), Subtract(-), Multiply(x), and Divide(/). The CNN model contains around 160k trainable parameters, making it easily deployable on less computation efficient devices.
The Dataset
The dataset is taken from Kaggle from this link except for images of the division sign. The images for the division are taken from this Kaggle Link.
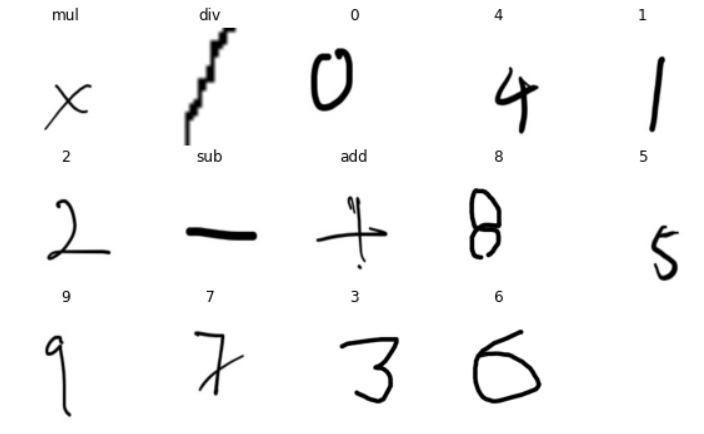
The images of the dataset can be visualized from the following collage —
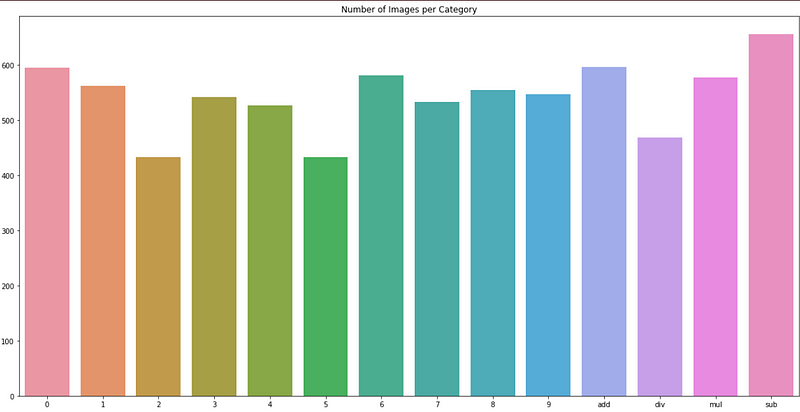
The data distribution can be seen in the following bar plot —
Preprocessing Step
The preprocessing step includes the following sub-steps —
- Convert three-channel images to Grayscale images.
- Apply a threshold to all the images to convert the images to binary.
- Resize the thresholded images to a uniform size of (32x32x1)
- Encode the non-categorical labels like ‘add’, ‘sub’ to categorical labels.
- Split the dataset into train and test set in 80–20 ratio.
The implementation of the steps mentioned above is as follows —
In line 6, OpenCV inbuilt function for thresholding is used. Line 12 contains the implementation of encoding the non-categorical labels using LabelEncoder class of sklearn. Finally, in line 15, the dataset is split into train and test sets.
The preprocessing step also includes converting the labels to one-hot vectors and normalising the images. The implementation is as follows —
Building the CNN Model
The CNN model has the following characteristics —
- Three Convolutional layers with 32, 32, and 64 number of filters, respectively.
- A MaxPool2D layer follows each Convolutional layer.
- Three Fully Connected layers follow the convolutional layers for classification.
The Keras implementation is as follows —
The L2 regulariser is used to avoid overfitting.
Model: "sequential" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= conv1 (Conv2D) (None, 32, 32, 32) 320 _________________________________________________________________ act1 (Activation) (None, 32, 32, 32) 0 _________________________________________________________________ max_pooling2d (MaxPooling2D) (None, 16, 16, 32) 0 _________________________________________________________________ conv2 (Conv2D) (None, 16, 16, 32) 9248 _________________________________________________________________ act2 (Activation) (None, 16, 16, 32) 0 _________________________________________________________________ max_pooling2d_1 (MaxPooling2 (None, 8, 8, 32) 0 _________________________________________________________________ conv3 (Conv2D) (None, 8, 8, 64) 18496 _________________________________________________________________ act3 (Activation) (None, 8, 8, 64) 0 _________________________________________________________________ max_pooling2d_2 (MaxPooling2 (None, 4, 4, 64) 0 _________________________________________________________________ flatten (Flatten) (None, 1024) 0 _________________________________________________________________ dropout (Dropout) (None, 1024) 0 _________________________________________________________________ fc1 (Dense) (None, 120) 123000 _________________________________________________________________ fc2 (Dense) (None, 84) 10164 _________________________________________________________________ fc3 (Dense) (None, 14) 1190 ================================================================= Total params: 162,418 Trainable params: 162,418 Non-trainable params: 0 _________________________________________________________________
Training the Model
Step Decay is used to decrease the value of the learning rate after every ten epochs. The initial learning rate is kept at 0.001. ImageDataGenerator class of Keras is used for data augmentation to provide a different image each time to the model. The batch size is saved at 128, and the model is trained for 100 epochs.
Performance of the Model
The performance metrics used are as follows —
- Loss and Accuracy vs Epochs plot
- Classification report
- Confusion Matrix
Loss and Accuracy vs Epochs plot —
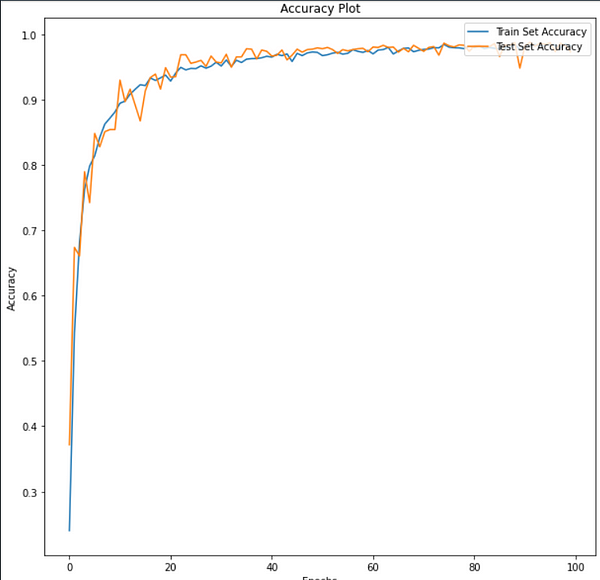
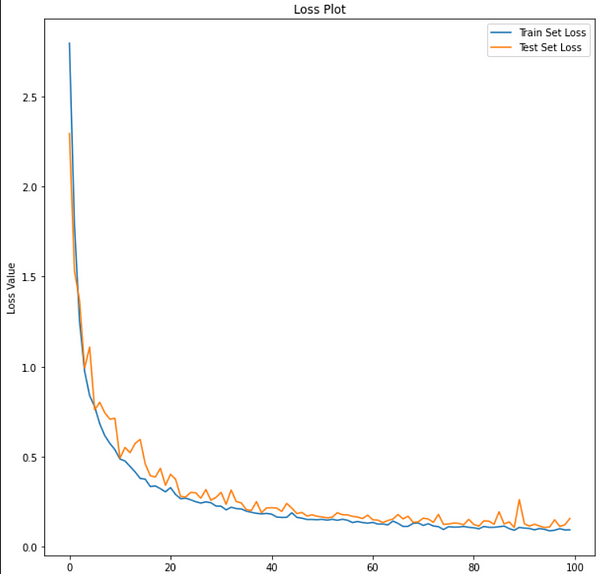
Classification Report —
precision recall f1-score support
0 0.94 0.97 0.96 113
1 0.99 0.93 0.96 115
2 0.99 0.99 0.99 97
3 1.00 0.97 0.98 116
4 0.94 0.99 0.97 101
5 1.00 0.85 0.92 82
6 0.89 0.99 0.94 120
7 0.93 1.00 0.97 86
8 0.98 0.97 0.97 127
9 0.98 1.00 0.99 102
10 1.00 0.96 0.98 113
11 1.00 1.00 1.00 84
12 0.99 0.99 0.99 114
13 1.00 0.99 1.00 150
accuracy 0.97 1520 macro avg 0.97 0.97 0.97 1520 weighted avg 0.97 0.97 0.97 1520
Confusion Matrix —
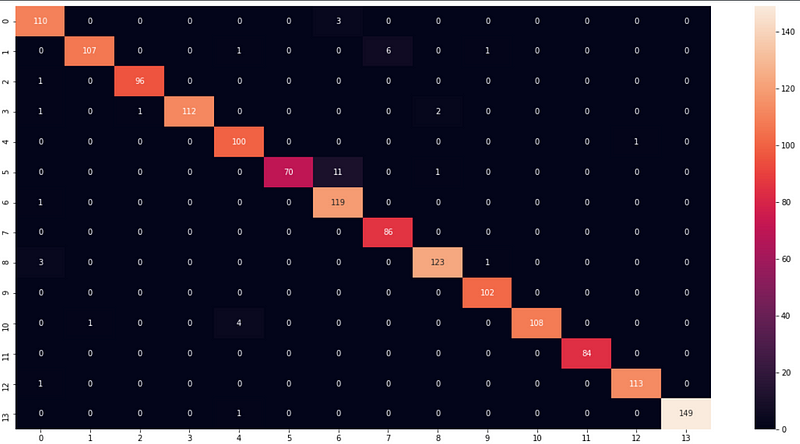
Testing the Model on Images
The pipeline includes reading the image, grayscale conversion, edge detection, contour detection, segmenting the digits and operators through detected contours, ROI extraction, preprocessing ROI, making predictions from the model on this ROI, and displaying the results on the original image.
The result is of passing an image to the pipeline is shown below —
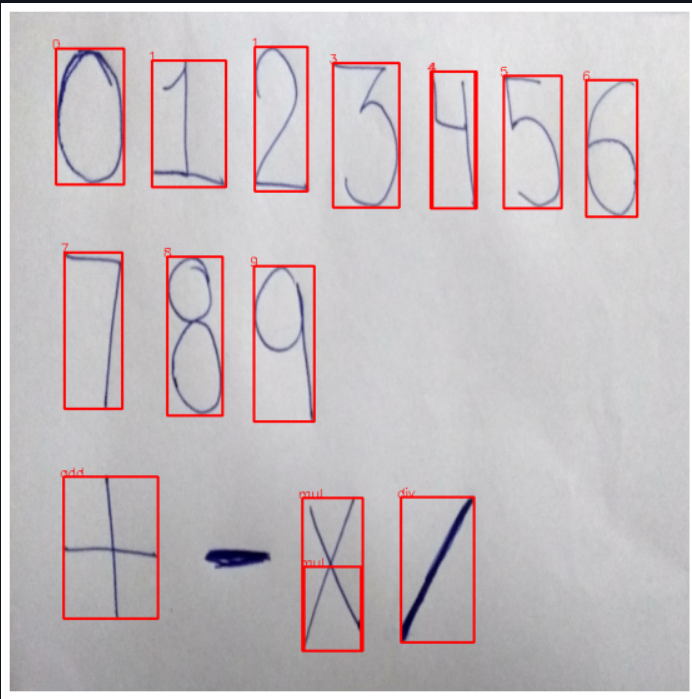
Building Pipeline for Expression Calculation
The implementation is almost similar to the pipeline mentioned in the previous section. The differences are listed below —
- Line 2 initializes the list to store the predictions.
- Line 37 appends the predictions to the ‘chars’ list.
- Lines 47 to 58 construct the string representation of the expression.
- Lines 59 and 60 evaluate the expression and print the value, respectively.

As mentioned earlier, the current implementation only recognizes four basic arithmetic operators and does not recognize the brackets. So, For example, the expression trecognizeed is 22+16×16. This expression is interpreted as 22+(16×16), and a similar convention is used for the pipeline.
Conclusion
The article summarizes the Handwritten Optical Character Recognition. The implementation recognizes handwritten digits and four arithmetic operators and takes Handwriting Recognition one step forward.
The pipeline can also evaluate the expression written. The level of the project can be increased further by including more mathematical operators and symbols and making the system more intelligent. The CNN model used has less than 250k parameters and can be easily deployed on edge devices.
This deployment is possible through the Cainvas Platform by making use of their compiler called deepC. Thus effectively bringing AI out on edge — in actual and physical real-world use cases.
Notebook Link: Here
Credit: YUVNISH MALHOTRA
Also Read: Intent Classification using LSTM