Train a deep learning model to respond to a specific word.

Audio wake word systems respond to a specific phrase (Cainvas, in this case). You may use your own word as a wake word which you can use later on to turn up your own IoT device.
The challenges in training models for low power devices are the available memory and computational resources. The model runs on-device without cloud connectivity.
In this article, the audio wake word is a specific word (hotword). The notebook takes background and hotword recordings as input for training the model.
Implementation of the idea on cAInvas — here!
The Dataset
The dataset uses recordings from the user to train the model and test it as well.
Background: Recordings of your usual background sounds, could be something as simple as someone reading a book or just talking to each other.
Hotword: Recordings of you spelling out your wake word (Cainvas, per say) separated by 2 second increments. This is the hotword that you will use to wake your system up.
Noise: We add silence and noise as in the following to enhance the quality of the dataset.
The total length of the labels is now 471.
The dataset is then divided into training and test sets at a ratio of 9:1.
Note
1. Quality of the resulting model depends on quality of dataset. For small datasets, false positives are expected to occur more (model predicts background noise as wake word).
2. Quality of dataset can be further improved by having a variety of speakers recording in different environments with different levels of background noise.
The model
We use a spectrogram operator at the beginning of the model. It uses STFT (Short-time Fourier transform) which is a Fourier-related transform used to determine the sinusoidal frequency and phase content of local sections of a signal as it changes over time.
The output is then fed to a chain of convolution layers which is then passed through a dense layer to give a prediction at the last sigmoid activation layer.
The model is compiled using the binary cross-entropy loss function because the final layer of the model has sigmoid activation function. The Adam optimizer is used and the accuracy of the model is tracked over epochs.
The model achieved an accuracy of ~95.8%.
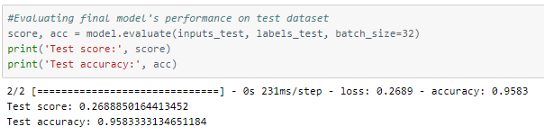
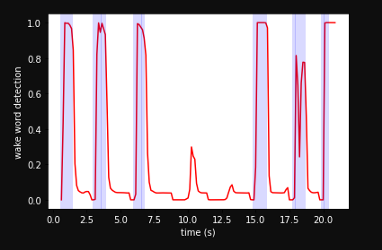
The metrics and predictions
A clip is used to test the model. The clip is a recording of the user talking and using the hotword now and then to see if the model is able to detect it properly. The graph below represents detection of the hotword as a high and the rest as low.
deepC
deepC library, compiler, and inference framework are designed to enable and perform deep learning neural networks by focussing on features of small form-factor devices like micro-controllers, eFPGAs, CPUs, and other embedded devices like raspberry-pi, odroid, Arduino, SparkFun Edge, RISC-V, mobile phones, x86 and arm laptops among others.
Compiling the model using deepC —
Head over to the cAInvas platform (link to notebook given earlier) to run and generate your own .exe file!
Credit: Rohit Sharma
Written by: Arnab Chakraborty
Also Read: Object Classifier Using CNN