Differentiating between a mosquito bite and a tick bite using deep learning.

There are so many different types of insects around us that tend to bite/sting us when they get close. Insect bites can result in itching, swelling, redness, or rashes. While some of these bites need no special attention, some can be lead to allergic reactions and can even be poisonous and need immediate medical care.
Here we will attempt to differentiate between mosquito bites and tick bites using neural networks.
Implementation of the idea on cAInvas — here!
The dataset
The dataset folder has 3 folders train, validation, and test. Each of these folders has 2 sub-folders named mosquito and tick containing respective category images.

The training set is almost balanced while the others are perfectly balanced!
The image_dataset_from_directory() function of the keras.preprocessing module is used to load the images into a dataset with each image having dimension 256×256 (default value of function parameter).
The class names are also viewed and stored for later reference. Class name array — [‘mosquito’, ‘tick’].
Visualization
A peek into the images in the dataset —
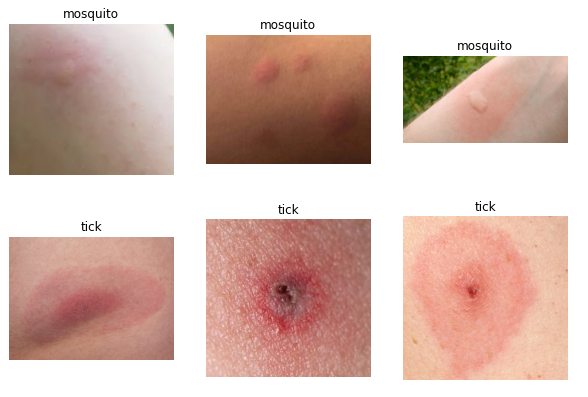
They are visually separable but let’s see how the model does!
Preprocessing
Normalization
The pixel values of these images are integers in the range 0–255. Normalizing the pixel values reduces them to float values in the range [0, 1] helping in faster convergence of the model’s loss function. This is done using the Rescaling function of the keras.layers.experimental.preprocessing module.
Augmentation
The dataset has only 47 images in total for both classes combined. This is not enough data to get good results.
Image data augmentation is a technique to artificially increase the size of the training dataset using techniques like scaling (or resizing), cropping, flipping (horizontal or vertical or both), padding, rotation, translation (movement along x or y-axis). Colour augmentation techniques include adjusting the brightness, contrast, saturation, and hue of the images.
Here, we will implement two image augmentation techniques using functions from the keras.layers.experimental.preprocessing module —
- RandomFlip — randomly flip the images along the directions specified as a parameter (horizontal or vertical or both)
- RandomZoom — random images in the dataset are zoomed (here 10%).
- RandomRotation — random images of the dataset are rotated through [x * 2* pi, y * 2 *pi] radians where x and y are given as parameter values representing fractions of 2*pi.
Feel free to try out other augmentation techniques!
The augmented dataset is appended to the original dataset thus doubling the entire sample count.
The model
We are using transfer learning, which is the concept of using the knowledge gained while solving one problem to solve another problem.
The model’s input is defined to have a size of (224, 224, 3).
The last layer of the VGG16 model (classification layer) is not included and instead, it is appended with a GlobalAveragePooling layer followed by a Dense layer with softmax activation and as many nodes as there are classes.
The model is configured such that the appended layers are the only trainable part of the entire model. This means that, as the training epochs advance, the weights of nodes in the VGG16 architecture remain constant.
The EarlyStopping callback function monitors the validation loss and stops the training if it doesn’t for 5 epochs continuously. The restore_best_weights parameter ensures that the model with the least validation loss is restored to the model variable.
The model is compiled using the sparse categorical cross-entropy loss function because the outputs are not one-hot encoded. The Adam optimizer is used and the accuracy of the model is tracked over epochs.
The model is trained first with a learning rate of 0.01 and then 0.001.

The model achieved 75% accuracy on the test set. Given that the test set has only 4 images, 3 of them were labeled correctly.
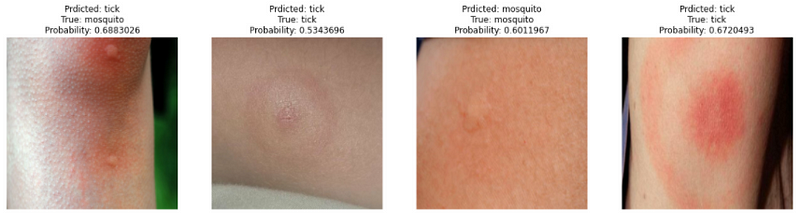
The low accuracy rate is due to the very few numbers of samples in the training set. Even after augmentation techniques, the dataset is small to obtain high results. This notebook is a proof of concept of how neural networks can be used to differentiate between insect bites.
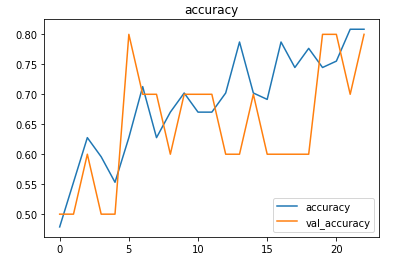
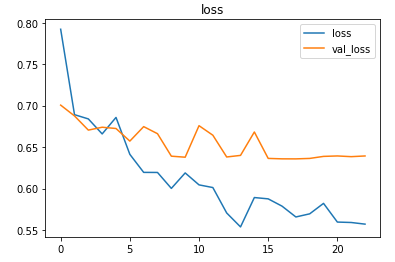
The metrics
deepC
deepC library, compiler, and inference framework are designed to enable and perform deep learning neural networks by focussing on features of small form-factor devices like micro-controllers, eFPGAs, CPUs, and other embedded devices like raspberry-pi, odroid, Arduino, SparkFun Edge, RISC-V, mobile phones, x86 and arm laptops among others.
Compiling the model using deepC —

Head over to the cAInvas platform (link to notebook given earlier) and check out the predictions by the .exe file!
Credits: Ayisha D