Neural machine translation (NMT) is an approach to machine translation that uses an artificial neural network to predict the likelihood of a sequence of words, typically modeling entire sentences in a single integrated model.
Language Translation is a key service that is needed by the people across the whole globe. We are going to talk about a Neural Machine Translator which translates English to French using a seq2seq NLP model. It uses a bi-directional LSTM neural network model to translate English To French.

Table of Content
- Introduction to cAInvas
- Source of Data
- Data Preprocessing
- Model Training
- Introduction to DeepC
- Compilation with DeepC
Introduction to cAInvas
cAInvas is an integrated development platform to create intelligent edge devices. Not only we can train our deep learning model using Tensorflow, Keras or Pytorch, we can also compile our model with its edge compiler called DeepC to deploy our working model on edge devices for production.
The Neural Machine Translator model is also developed on cAInvas and is a part of cAInvas Use-Case Gallery now. All the dependencies which you will be needing for this project are also pre-installed.
cAInvas also offers various other deep learning notebooks in its gallery which one can use for reference or to gain insight about deep learning. It also has GPU support and which makes it the best in its kind.
Source of Data
While working on any UsedCases from cAInvas gallary we don’t have to look for data manually.We can load the data in a dataframe by using pandas library. We just have to enter the following commands:
Running the above command will load the data in a dataframe which we will later use for model training.
Data Preprocessing
This step involves data cleaning and pre-processing our data for model training in order to achieve good performance and for better data visualization.
While loading the dataset we observed that we have two dataframes one containing English sentences and the other containing its french translations. So we will concatenate both dataframes into one. Next step involves removal of any punctuation in our dataframe.
Our next step is to find total number of unique words in both English and French Data which will define the vocab size. The final step involves tokenizing and padding our text data for both English and French text. For this we will use NLTK’s word_tokenize and TensorFlow’s pad_sequence.
Model Training
After creating the dataset next step is to pass our training data into our Deep Learning model to learn to learn to produce the translated French text by taking in English text. The model architecture used was:
Model: "sequential" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= embedding (Embedding) (None, 15, 256) 51200 _________________________________________________________________ lstm (LSTM) (None, 256) 525312 _________________________________________________________________ repeat_vector (RepeatVector) (None, 23, 256) 0 _________________________________________________________________ lstm_1 (LSTM) (None, 23, 256) 525312 _________________________________________________________________ time_distributed (TimeDistri (None, 23, 351) 90207 ================================================================= Total params: 1,192,031 Trainable params: 1,192,031 Non-trainable params: 0 _________________________________________________________________
The loss function used was “sparse_categorical_crossentropy” and optimizer used was “Adam”.For training the model we used Keras API with tensorflow at backend. .Here are the training plots for the model:
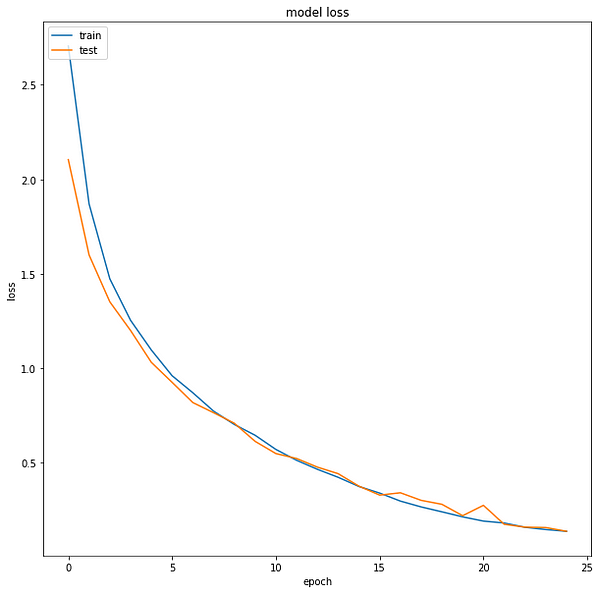
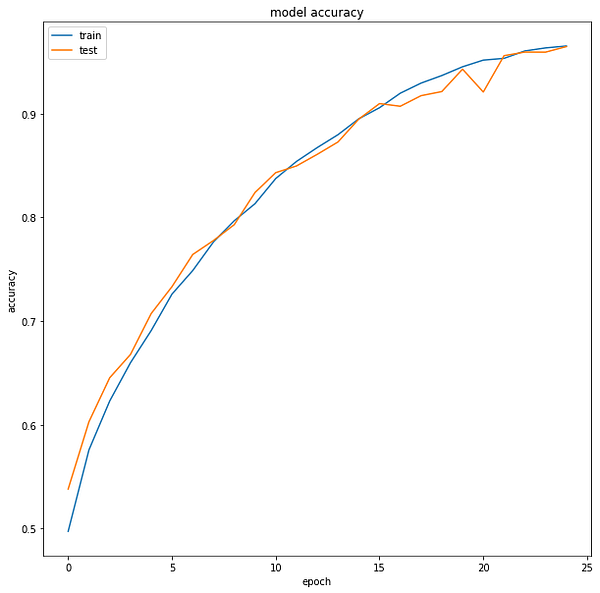
Introduction to DeepC
DeepC Compiler and inference framework is designed to enable and perform deep learning neural networks by focussing on features of small form-factor devices like micro-controllers, eFPGAs, cpus and other embedded devices like raspberry-pi, odroid, arduino, SparkFun Edge, risc-V, mobile phones, x86 and arm laptops among others.
DeepC also offers ahead of time compiler producing optimized executable based on LLVM compiler tool chain specialized for deep neural networks with ONNX as front end.
Compilation with DeepC
After training the model, it was saved in an H5 format using Keras as it easily stores the weights and model configuration in a single file
After saving the file in H5 format we can easily compile our model using DeepC compiler which comes as a part of cAInvas platform so that it converts our saved model to a format which can be easily deployed to edge devices. And all this can be done very easily using a simple command.
And that’s it, our Neural Machine Translator is trained and ready for deployment on edge devices.
Link for the cAInvas Notebook: https://cainvas.ai-tech.systems/use-cases/neural-machine-translation-english-to-french-app/
Credit: Ashish Arya
Also Read: Food Mnist Classification