Train a deep learning model to respond to the presence of certain objects in the image/video frame (person here).

Just as audio wake word systems respond to a specific phrase, visual wake word systems respond to the presence of certain objects in the image/frame. Such wake word systems are important in designing low power modules that wake up in response to external input.
The challenges in training models for low power devices are the available memory and computational resources. The models run on-device without cloud connectivity.
In this article, the visual wake word is the presence of a person. The notebook implements the classification of images from the COCO dataset into 2 classes — with person(s) or without.
COCO stands for Common Objects in Context and is a standard in the deep learning community for object detection, segmentation, image recognition, classification, and captioning.
Implementation of the idea on cAInvas — here!
The dataset
The dataset is derived from COCO 2017 and reduced to ~100 MB using the script here.
The dataset folder has 2 sub-folders — person and notperson containing images of the respective types. Each folder has 300 images making it a balanced dataset.
The images are loaded using the image_dataset_from_directory() function of the keras.preprocessing module specifying the image folder path, the dataset type (train/val), and the split ratio 80–20.
The training set has 480 images while the validation set has 120 images.

A peek into the class names —

Array index 0 stands for notperson and 1 stands for person.
Visualization
Let us look into a few images in the dataset —

Preprocessing
Normalizing the pixel values
The pixel values of the images are integers ranging from 0–255. Scaling them to float values in the range [0, 1] helps the model converge faster.
This is done using the Rescaling function of the keras.layers.experimental.preprocessing module.
The model
We are using transfer learning, which is the concept of using the knowledge gained while solving one problem to solve another problem.
The model’s input is defined to have a size of (256, 256, 3).
The last layer of the DenseNet121 model (classification layer) is not included and instead, it is appended with a GlobalAveragePooling layer followed by a Dense layer with softmax activation and as many nodes as there are classes.
The model is configured such that the appended layers are the only trainable part of the entire model. This means that, as the training epochs advance, the weights of nodes in the DenseNet121 architecture remain constant.
The model is compiled using the sparse categorical cross-entropy loss function because the final layer of the model has the softmax activation function and the outputs of the model are not one-hot encoded here. The Adam optimizer is used and the accuracy of the model is tracked over epochs.
The EarlyStopping callback function of the keras.callbacks module monitors the validation loss and stops the training if it doesn’t for 5 epochs continuously. The restore_best_weights parameter ensures that the model with the least validation loss is restored to the model variable.
The model was able to achieve ~93% accuracy on training with a learning rate of 0.01.

The metrics
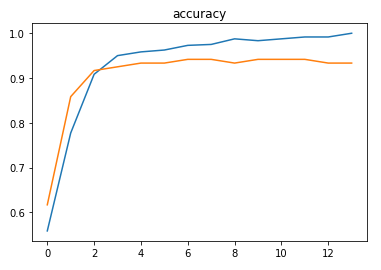
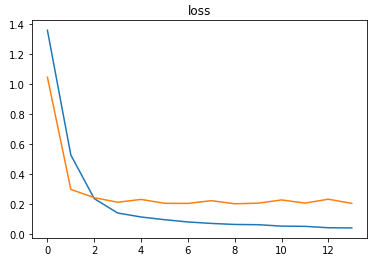
Predictions
Let’s look at the test image along with the model’s prediction —

deepC
deepC library, compiler, and inference framework are designed to enable and perform deep learning neural networks by focussing on features of small form-factor devices like micro-controllers, eFPGAs, CPUs, and other embedded devices like raspberry-pi, odroid, Arduino, SparkFun Edge, RISC-V, mobile phones, x86 and arm laptops among others.
Compiling the model using deepC —

Head over to the cAInvas platform (link to notebook given earlier) to run and generate your own .exe file!
Credits: Ayisha D
Also Read: Arrhythmia prediction on ECG data using CNN