
Potato is perhaps the most important food crop of the world. Potatoes are economical food as they provide a source of low cost energy to humans. They are a rich source of starch and contain a good amount of amino acids as well.
The potato crop grows in about 4 weeks after planting and weeds must be removed to gain an advantage for the crop. Our aim is to use Machine Learning in the identification of weed plants to develop a device which can segregate the weed plant from the potato crop without human intervention.
We use a dataset which contains images of potato and weed to create a model which can distinguish between the two. In order to access the dataset, please follow the following link. Our data contains 336 images for training and 75 images for validation.
After selecting our dataset, the next task is to go to such a platform which lets us train and prepare DNN models which can be deployed in webapps or IOT devices. For this purpose, we use Cainvas AITS Platform. This platform gives us access to train our models in jupyter notebooks using highly efficient GPUs.
We will start by importing all the libraries necessary for our training.
The following libraries cover our dependencies.
Next, we unzip our data to make it available in our workspace. After this, we define variables ‘train_path’ and ‘validation_path’ to define our training and validation splits of the dataset.
A very important step which needs to be taken before we start preparing our data is to visualize and view our data. For this part, we define several plotting functions and pass them our image directories. Using cv2 library, the images and read and displayed with the help of matplotlib library.


Since our images are less in number, we define training and validation image data generators to expand our dataset of training and validation images. This is done by artificially generating new images by processing the existing images. By random flipping, rotating, scaling and performing similar operations, we can create new images.
This creation is done with the help of ImageDataGenerator() function from the keras library. This preprocessing function is extremely helpful in dealing with image data. Next, we load our training and validation data through these image data generators and set an image input size of 64*64.
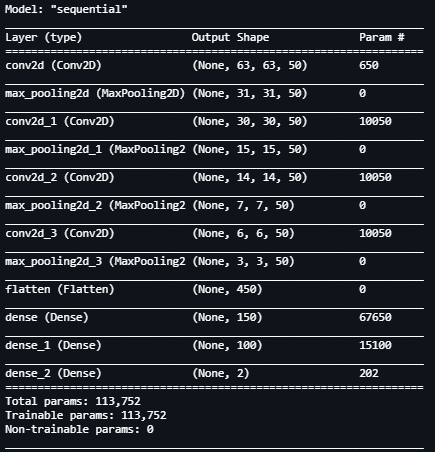
Now that we have our images which have been pre processed and are ready to be read by our Neural Network Model, we define the architecture for it. We define a Sequential model with the following layers having about 204k trainable parameters.
For our model, every 2 dimensional convolution layer having a filter size of 2*2 is followed by a Max Pooling 2 Dimensional layer which has a similar filter size.
Now, we begin training our model. In the beginning, we defined a batch size of 5 for the images. We use this parameter for defining steps per epoch and validation steps.
Since our model architecture is ready, we fit the training and validation images into the model with the help of fit_generator() function. Defining steps per epoch and validation steps with the help of image samples and batch size, we set the number of epochs as 50 and begin training.
Notice that by simply changing the batch size we can change the steps during training as well.
After our model is trained, we see that we’ve achieved the following statistics:
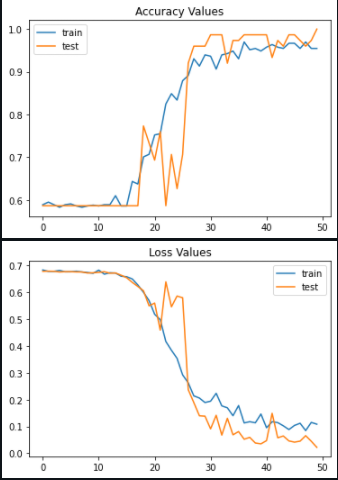
1. Training Accuracy: 95%
2. Validation Accuracy: 100%
3. Training Loss: 0.1
4. Validation Loss: 0.05
We confirm the above metrics by plotting accuracy and loss for both training loss with respect to number of epochs.
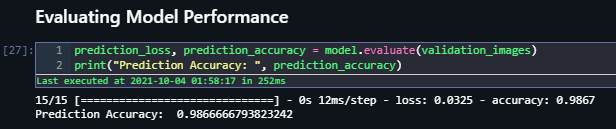
We will use other techniques and metrics as well to determine the performance of our model. Evaluating accuracy on the validation images for our model, we see that it achieves 98.6% accuracy. These results seem promising.
For our final check, let us randomly select an image from each category of images and predict it using the model.
We prepare a function that will help us predict the category of the image using our trained deep neural network model. The pred variable contains the prediction. If the value of pred is 0, the model predicts that the image belongs to potato plant, however, if it’s value is 1, the image belongs to weed plant.
Testing our model for random custom images, we get the following results:-


Machine Learning and Deep Learning have had great impacts in our life. The scope of improvement and growth in this field is beyond any limits. We’ve now reached the end of our project. If you want to access the full notebook, please follow this link.
Also Read: Dog Breed Classification App
Best of luck for your Machine Learning careers.
Cheers!
Notebook Link : Click Link
Credit : Kkharbanda