Let us build a Deep Learning Model which can read, understand and detect over 28 handwritten Arabic digits.

Being one of the six U.N. recognized languages, Arabic is the official language of about 1.8 million people across the globe. Talking about the spread of the language, it spread along with the growth of Islam around the world.
It gained vocabulary from Middle Persian and Turkish. In the Islamic world during the 8th century, knowledge of Arabic became a compulsion for everyone.
One can go on and on about the history and development of arabic language, however, it will not serve the purpose of this article. Today, we will learn how to use our Machine Learning and Deep Learning knowledge to recognize Arabic digits.
The first and foremost step for preparation of our model is to access the database. In order to do that, you can follow this link.
We find that our dataset has 4 CSV files:-
1. Training Images
2. Training Labels
3. Test Images
4. Test Labels
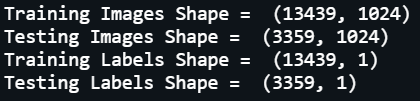
We will start by loading all the files using pandas library and observe the shape of the dataset.
Reading the image pixels from the csv file is our next step followed by their conversion to a numpy array.
In order to convert our training labels to a form which can be accessed by our model, we will use LabelBinarizaer(). Label Binarizer is a utility class to help create a label indicator matrix from a list of multiclass labels. After encoding the training labels, the next step is to resize the image data from the numpy array.
For our model, we will use an input size of 32 x 32. That is, each of our image will have a height and width of 32px each.
Since our data is almost ready for model preparation, we can visualize some of the images we are planning to use of training and testing our model. We write a simple function for visualizing a grid of 5 x 5 = 25 images ( 5 rows and 5 columns ).

To effectively visualize an image through pixel data, we use the following function and pass as input our first image of the training data and see the distribution of values for the handwritten arabic character.

After this short glimpse of the images, the next step is to split our images for training and testing parts using train_test_split() function from the ScikitLearn Library. For the purpose of our model, we use a training — test split of 80% and 20% respectively.
A good practice while preparing deep learning models is to use the callbacks feature of Keras. By using EarlyStopping() and monitoring validation loss, our model stops training if the validation loss does not reduce for 5 epochs. This way, we ensure a minimum loss value and also prevent overfitting upto some extent.
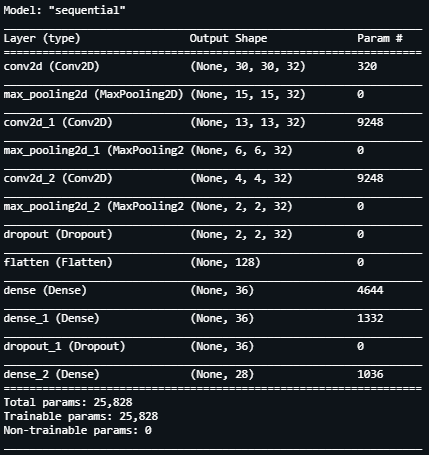
Defining the architecture of our Sequential model is the next step. Since we’re dealing with image data having a size of 32 x 32, we set up our first layer as a 2-Dimensional convolution layer followed by a max pooling layer having a filter size of 2×2.
This “block” is followed by 2 similar blocks, after which we add a Dropout layer. The main function of adding Dropout layers is to prevent over fitting. It randomly drops or ignores several layer outputs and reduces them to 0.
It encourages the neural network to learn a sparse network. Next we flatten the input variables followed by several Dense layers and have an output Dense layer with the activation function set to sigmoid.
When we print the model summary, we observe that our model has about 25,000 trainable parameters.
Compiling our model using the Adam optimizer and categorical crossentropy as our loss function, we begin training by setting a batch size of 50and initialize training for 100 epochs.
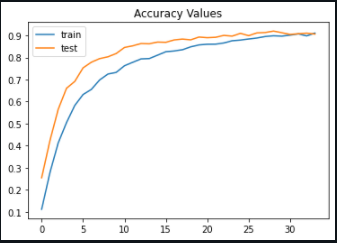
After our training terminates, we observe that we have achieved a validation accuracy of 90% and loss value as low as 0.2.
By plotting the accuracy and loss of our model, we notice that our training terminated before it could complete a cycle of 100 epochs, hereby reducing accuracy and ensuring minimum loss value.
Finally, to check the performance of our model, we plot a Confusion Matrix on the testing data and verify that indeed our model is accurate.
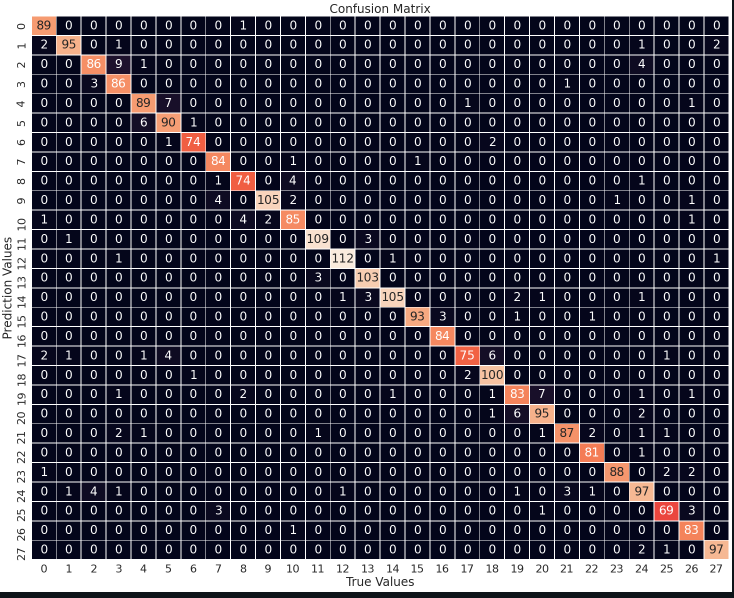

We see that our model is a success and can predict handwritten arabic characters with a great accuracy. We’ve put good use of our Machine Learning and Deep learning knowledge when we’ve prepared this model. In order to access the complete notebook, please follow this link.
Best of luck for your Machine Learning careers.
Cheers!
Notebook Link: Click Here
Credits: Kkharbanda