A model that uses Mel spectrogram images of the audio samples to recognize the spoken digit, which can be easily extended to one-word commands.

Communication is an important aspect of a human’s life. As technology is now an integral part of our lives, we tend to focus on different ways we can communicate our thoughts and intentions to the technology-powered devices around us.
Speech is one of the ways humans converse with each other. If we breakdown the process of understanding what is being spoken to us, the first segment would be recognizing the words. From the perspective of a machine, this segment would be transcription.
In this article, we will look into recognizing 1-second speech recordings of digits 0–9.
The cAInvas notebook implementation of the concept is here.
Dataset collection
The audio dataset used here is a subset of the Tensorflow speech commands dataset.
Each sample is 1-second long mono audio recorded at 8000 Hz.
The dataset is a balanced one with ~2360 samples in each class.
Extraction of features
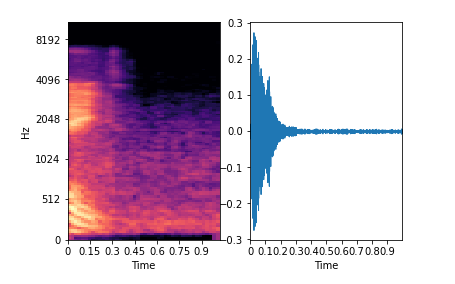
There are many ways to represent audio data, like, waveform, MFCCs, Mel spectrograms, spectrograms, and many more.
Among them all, the Mel scale is a closer representation of the human audio perception than the standard scale. Thus, the Mel spectrogram images of the audio recordings are extracted to be used as input to the model.
The code to extract them are to be executed only once and it creates the following output:
- A CSV reference file
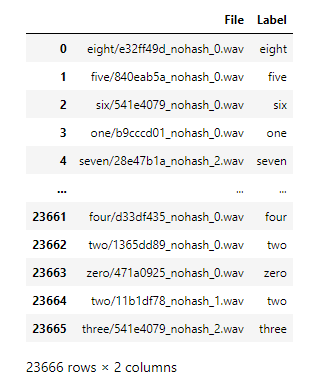
- Mel spectrogram images of all the audio samples
The dataset included in the notebook has the following:
- 10 folders, one for each digit. These folders have Mel spectrogram images of corresponding audio samples.
- 10 samples, one for each digit, from the dataset to help the notebook user understand the dataset better as the original samples are not included here.
- 4 user recorded external samples not present in dataset (train or val) to evaluate the model’s performance on external data.
Input to the model
The dataset of images is split into train and validation sets in the 90–10 ratio. The training set has 21300 images and the val set has 2366.
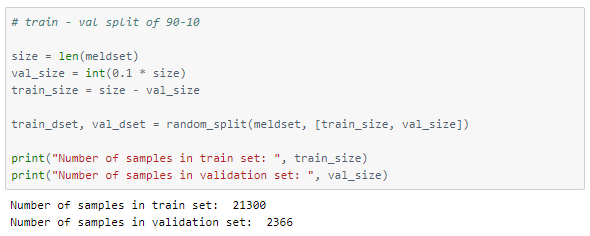
Each image is of size 54×55.
The dataset class is described as follows —
The model
The model has six consecutive Convolution2D-Maxpooling2D layers, followed by a flattening layer. This is followed by three dense layers where the last layer has ten nodes with softmax activation function.
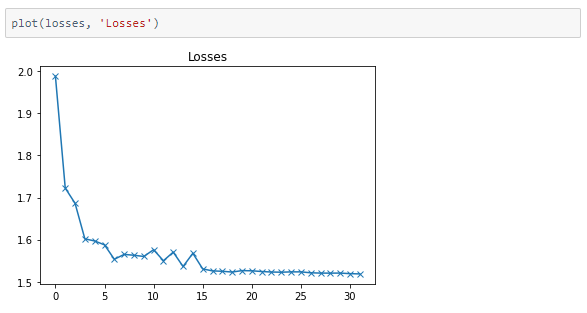
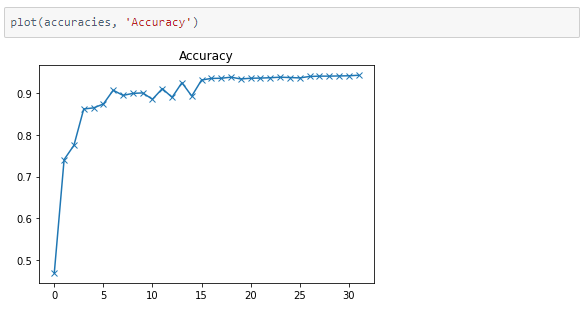
Training and testing
The model was trained for 16 epochs with a learning rate of 0.001 and 16 more with a learning rate of 0.0001.
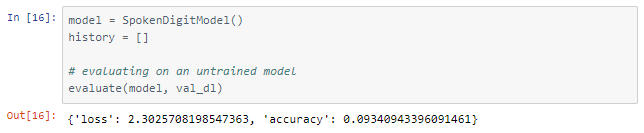

We were able to achieve 94.35% accuracy on the validation set.
The metrics
Prediction on external data
Head over to the notebook to listen to the external audio sample and see how the model performs!
deepC
deepC library, compiler, and inference framework is designed to enable and perform deep learning neural networks by focussing on features of small form-factor devices like micro-controllers, eFPGAs, cpus and other embedded devices like raspberry-pi, odroid, arduino, SparkFun Edge, risc-V, mobile phones, x86 and arm laptops among others.
Compiling the model using the deepC compiler —
A similar approach can be used to predict one-word audio samples like the ones in the tensorflow dataset mentioned in the notebook above.
Credit: Ayisha D
Also Read: Heartbeat Anomaly Detection