
What if I tell you, you can generate your very own stories, poems, texts using deep learning. Fascinating right? In this, article we’ll be discussing more about how this is achievable in-depth.
We’ll be working on RNN, and for that, we’ll be using LSTM. Now, what is LSTM?
Long Short Term Memory(LSTM) unit can have a memory about the previous data, hence can generate a new pattern using previous data. You can refer to the picture attached below for more clarification.
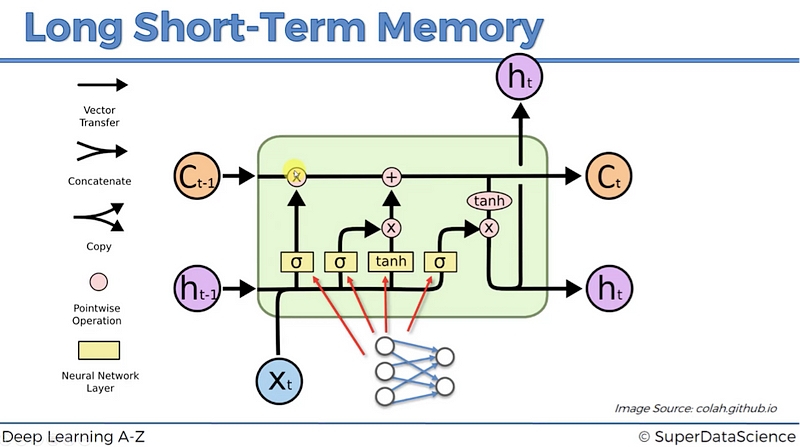
For a better understanding of the working of an LSTM one can refer to the above article.
In this project, we will be working with Keras to generate text. I have used a very famous speech by Priyanka Chopra as input, feel free to experiment around with any other text of your choice.
For the very initial steps, we are just importing the necessary libraries and the data. Check out how your data looks and perform some basic preprocessing on the text like removing punctuations and special characters etc. so that your text is good enough to build the required model on.
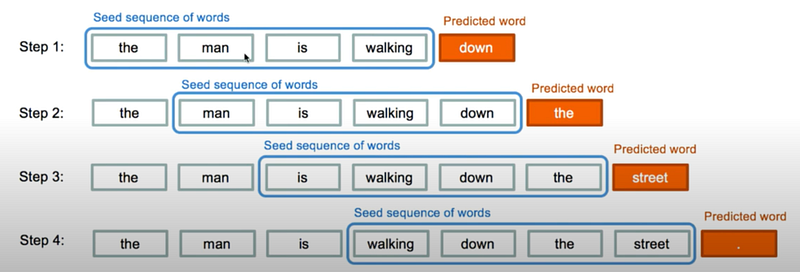
We need to work on the same lines, as of above snapshot. Now for that, we finally need lines from our processed data in such a way that each line contains (50 + 1) words, 50 would be the number of words given to the model each time starting from the very beginning, and 51st word is for prediction purposes.
You can refer to the above lines of code for more clarity if is it getting somewhat confusing.
Finally, we will import the libraries necessary to build our model.
As we all know machines and neural networks cannot work on text data directly, they simply don’t recognize it. Hence, we need to convert our words in the sentences to some numerical values such that our model can figure out what exactly is going on. For this purpose especially, in Natural Language Processing, “Tokenization” plays are vital role.
Tokenization serves as the base of almost every possible model based on NLP. It just assigns each unique word a different number which we can check out by printing tokenizer.word_index.
Now we’ll simply divide each sentence in such a way that X = first 50 words and y = 51st word.
The structure of our sequential model would be somewhat like this:
and for compilation of the model, I have used: optimizer =”adam”, loss =”categorical_crossentropy”, and metrics = [“accuracy”].
I found this video very beneficial for basic understanding. You can have a look for a better understanding of loss functions.
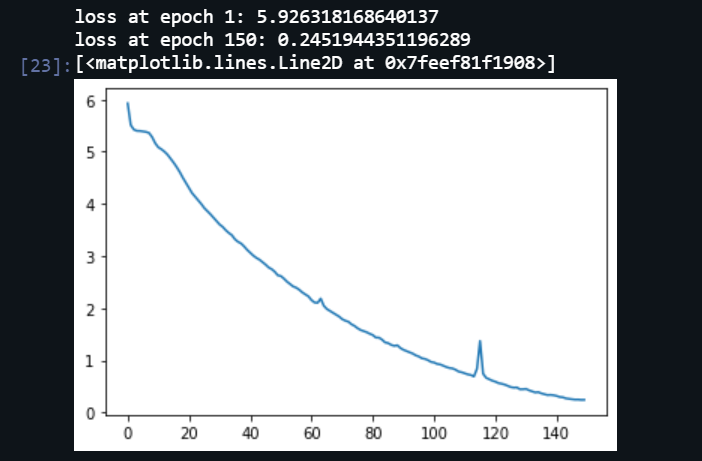
Finally, I have trained my model keeping epochs value as 150. You can really, play around with this for better accuracy or even less loss. In my case, I got 97.66% accuracy using above mentioned parameters. And if we talk about the loss, I have attached the graph below I got.
If your model takes a lot of time in training you can save the once trained model for future use using load_model from tensorflow.keras.models. Although, it is a good practice to save your trained model like this.
Lastly, we will provide our model with any random line from our corpus we will call this line seed_text and now we can predict/generate what so ever number of words using the following function:
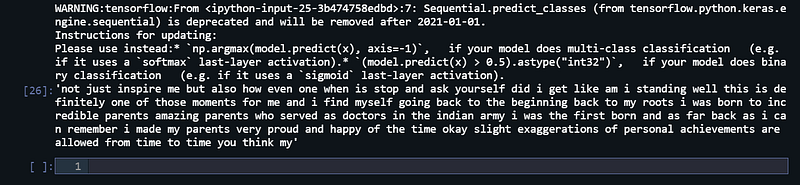
I predicted the next 100 words with 97.66% accuracy and my predicted text looks like this, what about you.
Platform: cAInvas
Code: Here
Credit: Bhavyaa Sharma