Building a Deep Learning Model to identify unreliable news articles

What is Fake news?
Fake news is false or misleading information presented as news. It often aims to damage the reputation of a person or entity or make money through advertising revenue.
However, the term does not have a fixed definition and has been applied more broadly to include any type of false information, including unintentional and unconscious mechanisms, and also by high-profile individuals to apply to any news unfavorable to his/her personal perspectives.
Aim
To develop a Fake News Classifier using Bidirectional Long Short Term Memory (LSTM) using Python programming Language and Keras on Cainvas Platform.
Prerequisites
Before getting started, you should have a good understanding of:
- Python programming language
- Keras — Deep learning library
Dataset
we are going to use the train.csv dataset to train the model and then we do predictions for the test.csv dataset.
you can download these CSV files from Kaggle:
URL: https://www.kaggle.com/c/fake-news/data
Importing all the required libraries
let’s import all the required libraries:
https://gist.github.com/c008852b9f8e98e011489cf48375586d
Load and Process Data
Let’s load our data file train.csv using pandas.
https://gist.github.com/f91776dbb8585c0cb7cbcef04f110f4c
Output:
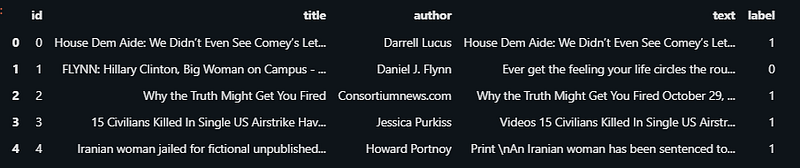
drop the nan values:
https://gist.github.com/095c0d59ee03d64134407c6da107e990
load X and y with Independent and dependent features:
https://gist.github.com/690eee57b39458f059f82d042c762725
One-hot Representation:
Vocabulary size:
https://gist.github.com/93d9b3df18bfffe29ae7eac16293f608
Getting a copy of Independent features:
https://gist.github.com/df9fe2171500fb91e9d902978e911c19
Downloading stopwords:
https://gist.github.com/10091208e5102c17835422afa940a48c
we are using nltk’s stopwords method to remove stopwords from our data, NumPy for array operations, and pandas to process data.
Dataset Preprocessing:
https://gist.github.com/0fa9416a96c5b5d783eecebe2317114d
output:
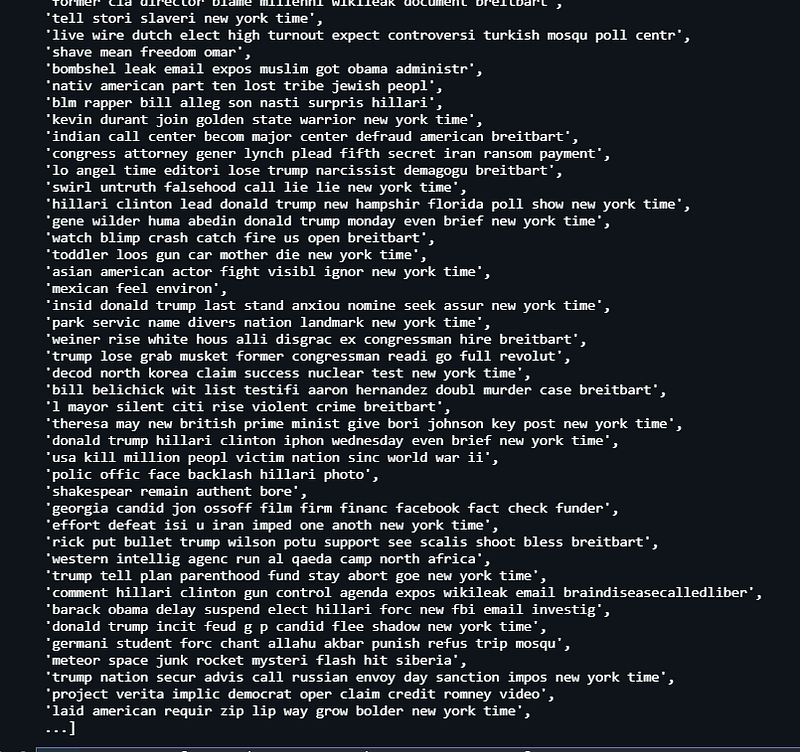
https://gist.github.com/7a83701eca6fd0d78d98e2c2ff26b638
output:
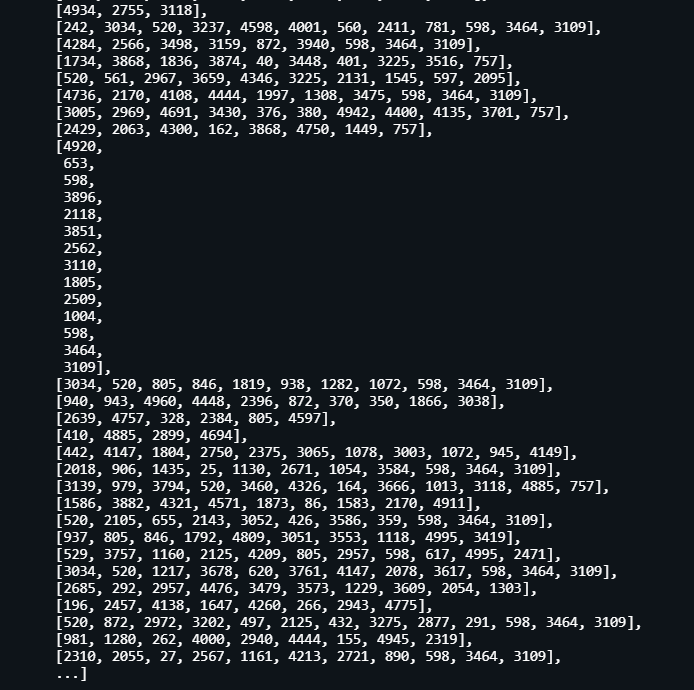
Embedding Representation:
refer to: https://towardsdatascience.com/neural-network-embeddings-explained-4d028e6f0526
https://gist.github.com/e4dca027ca404eed670ee4c000e9301a
output:

Building the model:
https://gist.github.com/de3339c249e07023c68bd1546be6a8e4
output:
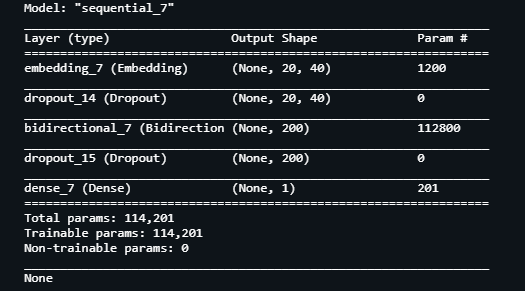
train test split:
https://gist.github.com/865dcadc4e4c805df6ef2bc37bb75098
here we use sklearn.model_selection package to split the data into train data and test data
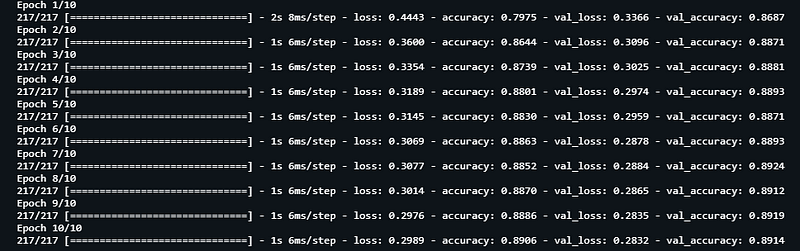
Training Model:
https://gist.github.com/0f4822656a6161c4ad1fd956990134f3
output:
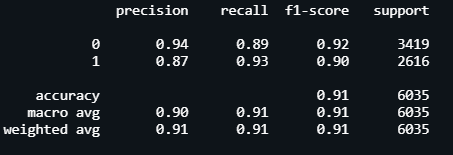
Predicting and Heat Map:
https://gist.github.com/63ed9ccb8d14ba6ea0bc4d4bc5bea70f
output:

Accuracy of the Model:
https://gist.github.com/5887a633b70409158aebbd8970373185
output:

https://gist.github.com/dea3e937e81d21d143516c2b3e9c45db
output:
Loading the test data:
https://gist.github.com/be59f84b242719a354efc3ebc651635f
output:

Making Predictions for test data:
https://gist.github.com/d7c0c24c43bd31a65711cb066b2ebfdc
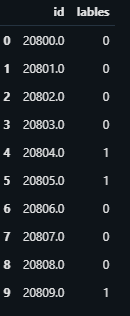
Joining the test data and predicted labels:
https://gist.github.com/fb81e9eb5bc490dd6b0c5eeea95e20b1
output:
URL to access the Notebook: https://cainvas.ai-tech.systems/use-cases/fake-news-classification-app-using-lstm/
Conclusion
We’ve trained our simple Bidirectional LSTM model on a fake news dataset and got an accuracy of 90%. There are many other machine learning models which perform much better but let’s admit it Machine Learning models require a lot of feature engineering and data wrangling. We are using a deep learning model to let the model figure everything out on its own.
Credit: Om Chaithanya V
Also Read: Malaria Parasite Detection using a Convolutional Neural Network on the Cainvas Platform