
The importance of maintaining civility on an online forum cannot be overstated. Cyberbullying is defined as “willful and repeated harm inflicted through the medium of electronic text.”
It involves sending degrading, threatening, and/or sexually explicit messages and images to targets via websites, blogs, instant messaging, chat rooms, e-mail, cell phones, websites and personal online profiles. As a result, detecting and deleting poisonous communication from public forums is a vital duty that is impossible for human moderators to do.
Toxic comment categorization refers to the classification of several forms of toxic comments into one or more categories such as ‘toxic,’ ‘severe toxic,’ ‘obscene,’ ‘threat,’ ‘insult,’ and ‘identity hate.’ The topic is particularly intriguing because of the intense debates about how poisonous information on the internet has impacted society’s general health.
Data-set
https://www.kaggle.com/c/jigsaw-toxic-comment-classification-challenge
The data-set can be availed through the above link.
The data utilized consists of a large number of Wikipedia comments that have been categorized according to their relative toxicity by humans.
- train.csv — the training set, contains comments with their binary labels
- test.csv — the test set, you must predict the toxicity probabilities for these comments.
Importing data-set can be done through the following lines of code:
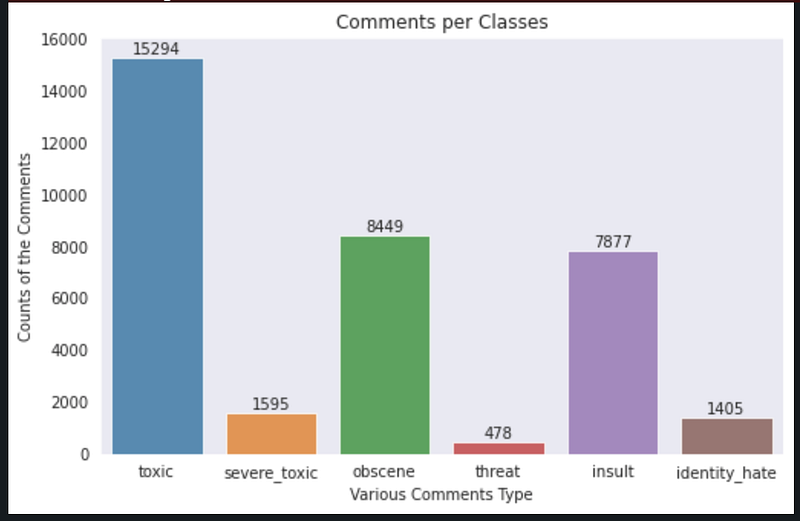
Visualization:
Number of comments per each class label is visualized and shown below
Tokenization:
In Natural Language Processing (NLP), tokenization is a typical job. The basic components of Natural Language are tokens. Tokenization is the process of breaking down a large chunk of text into smaller tokens. Tokens can be words, characters, or subwords in this case.
Model Building:
A neural network is build with two layer, 1st with ‘tanh’ as activation function and the later with ‘softmax’ activation.

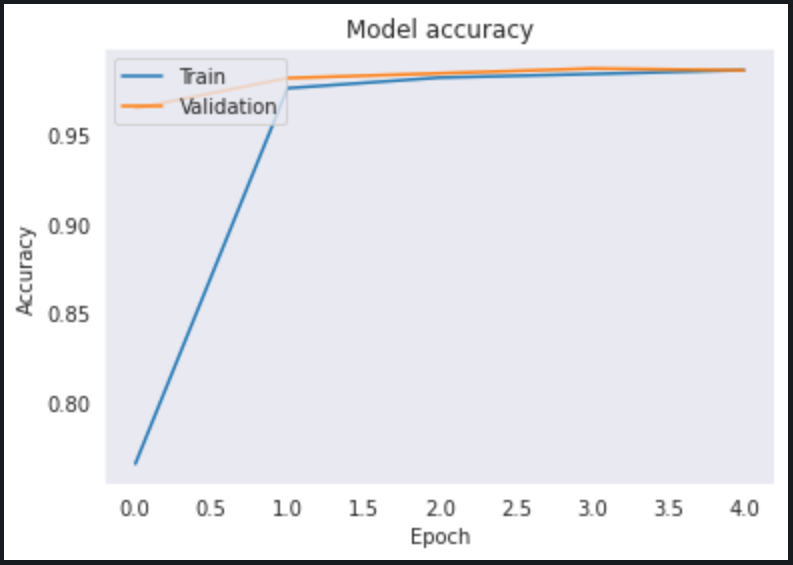
A training accuracy of 98.59% is achieved with built network.
Evaluation:
Checking the build model on test data

Testing accuracy of 98.8% is achieved
Conclusion:
A deep learning model to classify toxic comments is built with accuracy of 98.8%.
Platform: cAInvas
Code: Here
Credit: Dheeraj Perumandla
Also Read: Text generation using LSTM