Identify the type of star using its characteristics and neural networks.

Classification of stars based on their characteristics is called stellar classification.
Here we classify them into 6 classes — Brown Dwarf, Red Dwarf, White Dwarf, Main Sequence, Supergiant, and Hypergiant.
Implementation of the idea on cAInvas — here!
Dataset
On Kaggle by Deepraj Baidya | Github
The dataset took 3 weeks to collect for 240 stars which are mostly collected from the web. The missing data were manually calculated using equations of astrophysics.
The dataset is a CSV file with characteristics of a star like luminosity, temperature, colour, radius, etc that help classify them into one of the 6 classes — Brown Dwarf, Red Dwarf, White Dwarf, Main Sequence, Supergiant, Hypergiant.
There are 6 input attributes and 1 target column.
Preprocessing
Looking into the values of the ‘Star color’ column —
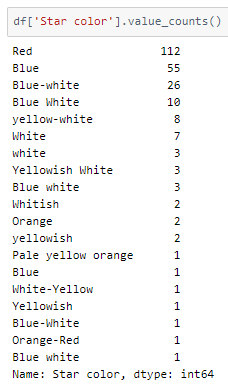
There are many shades of colours mentioned, some similar like Yellowish white and White-Yellow, and many spelling for blue-white.
We can identify 5 basic colours from the given list — blue, white, yellow, orange, and red. Let’s rewrite the column as 5 columns with multilabel values.
Now, the Spectral class column —
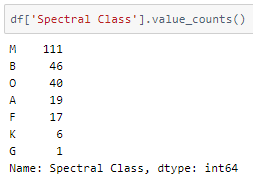
The values in this column do not have any range dependency. They are one hot encoded using the get_dummies() function of the pandas library. The drop_first parameter is set to True.
This means that if there are n categories in the column, n-1 columns are returned instead of n. i.e., each value is returned as an n-1 value array. The first category is defined by an array with all 0s while the remaining n-1 category variables are arrays with 1 in the (i-1)th index of the array.
The target columns have 6 class values that do not have any range dependency. They are one hot encoded using the get_dummies() function of the pandas library with drop_first set to False.
Let’s look into inferences derived from the dataset based on its values using the df.describe() function.
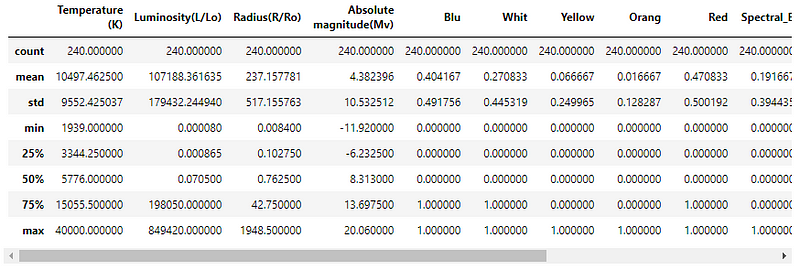
The range of values in the attributes and their standard deviation differ across the dataset. This can result in uneven weightage of attributes while training the model.
The dataset is split into train-validation-test before standardization (mean = 0, sd = 1).
The train set has 192 samples, the val and test set have 24 samples each.
The StandardScaler function of the sklearn.preprocessing module is used to implement this concept. The instance is first fit on the training data and used to transform the train, validation, and test data.
The model
The model is a simple one with 3 Dense layers, 2 of which have ReLU activation functions and the last one has a softmax activation function that outputs a range of values that sum up to 1 (probability values for the 6 classes).
As it is a classification problem where the targets are one-hot encoded, the model is compiled using the categorical cross-entropy loss function. The Adam optimizer is used and the accuracy of the model is tracked over epochs.
The EarlyStopping callback function of the keras.callbacks module monitors the validation loss and stops the training if it doesn’t decrease for 5 epochs continuously. The restore_best_weights parameter ensures that the model with the least validation loss is restored to the model variable.
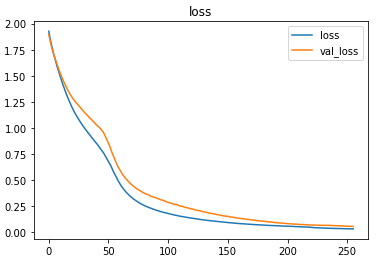
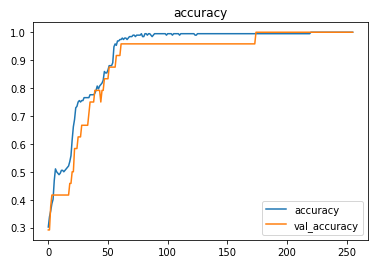
The model was trained with a learning rate of 0.001 and an accuracy of ~100% was achieved on the test set.

The metrics
Prediction
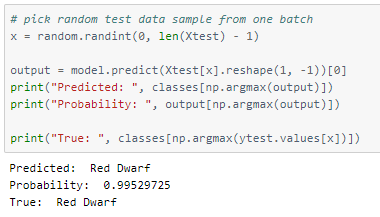
Defining the classes according to their array indices —

Let’s perform predictions on random test data samples —
deepC
deepC library, compiler, and inference framework are designed to enable and perform deep learning neural networks by focussing on features of small form-factor devices like micro-controllers, eFPGAs, CPUs, and other embedded devices like raspberry-pi, odroid, Arduino, SparkFun Edge, RISC-V, mobile phones, x86 and arm laptops among others.
Compiling the model using deepC —
Head over to the cAInvas platform (link to notebook given earlier) and check out the predictions by the .exe file!
Credits: Ayisha D
Also Read: Online Shopper’s Intention Prediction — on cAInvas