Identify the breed of the sheep in the image using neural networks.

Do you know how many breeds of sheep are out there? Many of us do not know their names, let alone recognizing them. This task requires expertise and becomes easier with experience.
For curious minds, a model that helps recognize the breed of sheep is helpful. As for the expert minds, this is a companion. From keeping count to monitoring their movement, this helps in reducing the time and effort required for the task.
Here, we attempt to classify face-focussed images of sheep into 4 breeds — Marino, Poll Dorset, Suffolk, and White Suffolk.
Implementation of the idea on cAInvas — here!
The dataset
This data is originally the efforts of Abu Jwade Sanabel et al. The team collected the data from a real farm in Australia. Data
The dataset has 1680 images of sheep, focussed on their faces, belonging to 4 classes — Marino, Poll Dorset, Suffolk, White Suffolk.
1344 of these are used for training and 336 are used for testing.
The images are loaded using the image_dataset_from_directory() function of the keras.preprocessing module by specifying the subset as training or validation.
Label mode — ‘categorical’ indicates that the class names are category-based and not range-based. This results in them being one-hot encoded when passed as targets to the model while training.
Looking into the spread of values across the image classes —

This is a well-balanced dataset.
Visualization
A peek into the images in the dataset —

How easy is it for you to differentiate between them?
Preprocessing
Normalization
The pixel values of these images are integers in the range 0–255. Normalizing the pixel values reduces them to float values in the range [0, 1]. This is done using the Rescaling function of the keras.layers.experimental.preprocessing module.
This helps in faster convergence of the model’s loss function.
The model
This is a sequential model with Conv2D-Conv2D-MaxPool2D blocks followed by Dense layers.
The EarlyStopping callback function (keras.callbacks module) monitors the validation loss and stops the training if it doesn’t for 5 epochs continuously. The restore_best_weights parameter ensures that the model with the least validation loss yet is restored to the model variable.
The model is compiled using the categorical cross-entropy loss function as the final layer of the model has the softmax activation function and the outputs of the model are one-hot encoded. The Adam optimizer is used and the accuracy of the model is tracked over epochs.
The model is trained first with a learning rate of 0.0001 which is then reduced to 0.00001.

The model achieved around 86.6% accuracy on the test set.
Plotting a confusion matrix to understand the results better —
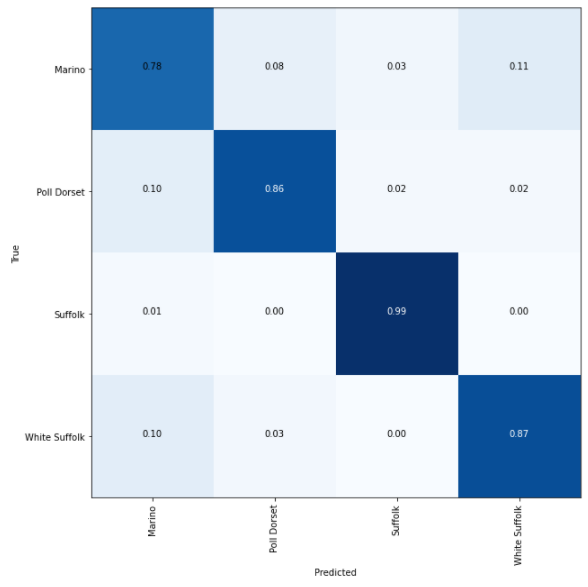
A larger dataset can help deliver better results and fewer false positives.
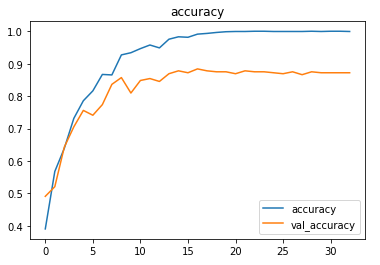
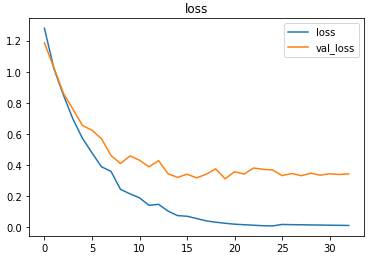
The metrics
Prediction
Let’s look at the test image along with the model’s prediction —

deepC
deepC library, compiler, and inference framework are designed to enable and perform deep learning neural networks by focussing on features of small form-factor devices like micro-controllers, eFPGAs, CPUs, and other embedded devices like raspberry-pi, odroid, Arduino, SparkFun Edge, RISC-V, mobile phones, x86 and arm laptops among others.
Compiling the model using deepC —
Head over to the cAInvas platform (link to notebook given earlier) to run and generate your own .exe file!
Credits: Ayisha D