Identifying whether the given text is spam or not (ham).

Spam texts are unsolicited messages usually sent for the purpose of advertising. While this helps a product reach consumers, it can be a source of unwanted input/communication to the consumer.
While reaching out to consumers in mass in order to increase the public presence of their product may seem harmless it is important to remember that spam messages, in many cases, include phishing attempts, non-commercial agenda propagation, or any other prohibited content/intent. These can put the consumer at the receiving end at risk.
There are many ways a spammer can reach you — SMS, calls, e-mails, web search results, etc.
Here, we classify text messages into two categories — spam or not, based on their content.
Implementation of the idea on cAInvas — here!
The dataset
Almeida, T.A., Gómez Hidalgo, J.M., Yamakami, A. Contributions to the Study of SMS Spam Filtering: New Collection and Results. Proceedings of the 2011 ACM Symposium on Document Engineering (DOCENG’11), Mountain View, CA, USA, 2011. Website | UCI
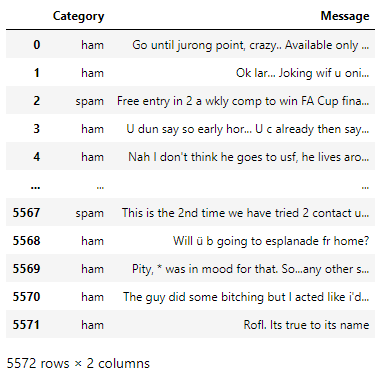
The dataset is a CSV file with 5572 messages falling into one of two categories — ham and spam.
Preprocessing
Dropping repeated rows
A few rows in the dataset are repeated. Let us drop them to get a dataset with unique rows.


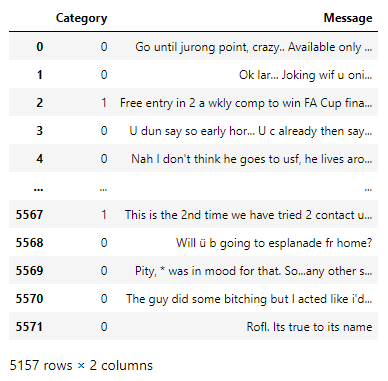
The dataset now has 5157 rows of which 4516 are ham and 641 are spam. It is not a balanced dataset but let us try training on it anyway.
Encoding the category values
The target column has label values that are to be converted into integer values depicting classes for training.
Data cleaning
The text in the messages needs to be preprocessed before giving as input to the model.
Defining a few functions to carry out the preprocessing —
- removing the HTML tags and URLs
- keeping only the alphabets, i.e., removing punctuations, special characters, and digits
- remove recurring characters. When we text, we tend to extend characters for emphasis or due to excitement. For example, ‘heyyyyyy’. Multiple occurrences of the same letter are reduced to 1. That is, the above is shortened to ‘hey’. But there are words in the English language that have consecutive recurring characters like wool, hello, etc. This is why we truncate characters that occur more than twice consecutively. Instances with 3 consecutive recurring characters are rare.
The list of stop words is also defined to be used later.
Snowball stemmer of the nltk.stem module is used to get the root of the words in the message.
The words in both categories are stored separately for visualization later.
Here, we have skipped the filtering of stop words as along with the context, the style of the text is also a contributing factor.
The cleaned sentences are added as a column in the dataset.
Train-validation-test split
Using an 80–10–10 ratio to split the data frame into train-validation-test sets. The train_test_split function of the sklearn.model_selection module is used for this. These are then divided into X and y (input and output) for further processing.
The train set has 4125 samples, the validation set and test have 516 samples each.
TF-IDF vectorization
There are 2 ways of implementing the TF-IDF vectorization —
- TF-IDF vectorizer
- CountVectorization followed by TF-IDF transformer
The CountVectorization function of the keras.preprocessing.text module is used to convert the text into a sequence of integers representing token counts.
The cleaned messages are given as input and a sparse matrix of values is returned. The TF_IDF transformer takes into account the frequency of the words in the dataset. This is used to scale down the impact of frequently occurring words in the corpus.
Defining the input and output to the model (X is the input and y is the output) —
Visualization
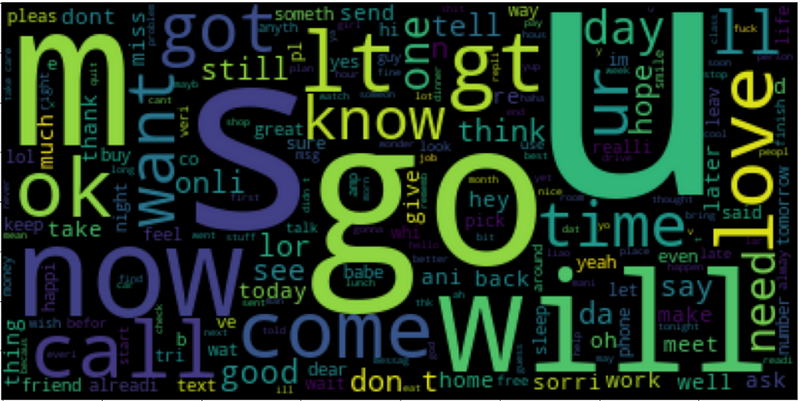
Looking at the words that are important/frequent in both categories.
The WordCloud function is used to visualize the words. The frequency of the words in the corpus are directly proportional to their size in the figure

The model
The model used is a simple one with 3 Dense layers, 2 of which have ReLU activation functions and the last one has a Sigmoid activation function that outputs a value in the range [0, 1].
Since this is a binary classification problem, the model is compiled using the binary cross-entropy loss function and the Adam optimizer is used and the accuracy of the model is tracked over epochs.
The EarlyStopping callback function of the keras.callbacks module monitors the validation loss and stops the training if it doesn’t decrease for 5 epochs continuously. The restore_best_weights parameter ensures that the weights of the model with the least validation loss are restored to the model variable.
The model was trained with a learning rate of 0.0001 and achieved an accuracy of ~98.8% on the test set.
Since this is an unbalanced dataset, the f1 score is calculated using the function of the sklearn.metrics module.

Plotting a confusion matrix to understand the results better —
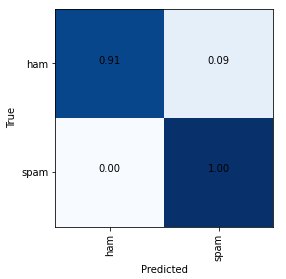
A significant percentage of the ham messages are classified as spam. A larger dataset with more instances of spam messages would help in avoiding false positives.
The metrics
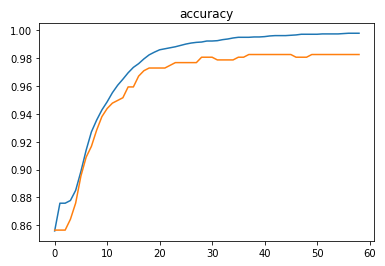
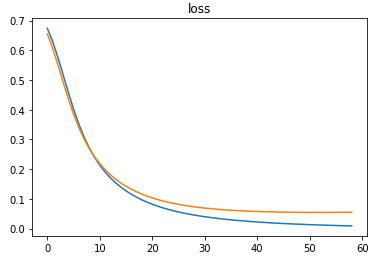
Prediction
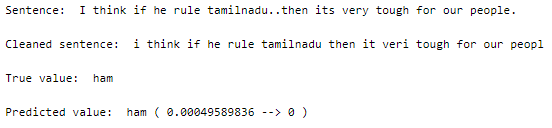
Let us perform predictions on random test samples —
The text sample is taken from the original CSV file, cleaned, vectorized, and then input to the model as an external sample would have to go through the same process.
deepC
deepC library, compiler, and inference framework are designed to enable and perform deep learning neural networks by focussing on features of small form-factor devices like micro-controllers, eFPGAs, CPUs, and other embedded devices like raspberry-pi, odroid, Arduino, SparkFun Edge, RISC-V, mobile phones, x86 and arm laptops among others.
Compiling the model using deepC —

Head over to the cAInvas platform (link to notebook given earlier) to run and generate your own .exe file!
Credits: Ayisha D